
LLMs are great at generating text, which makes them pretty good at writing code. But, in their current state, using LLMs for code generation, particularly when it comes to generating complex code, isn’t straightforward. There are many failure points along the way. Some of the most common problems are:
- Logical Errors: LLMs often misinterpret the logical requirements of a task, leading to incorrect or nonsensical code behavior.
- Incomplete Code: Important sections of code can be left out
- Misunderstanding Context: Models may fail to grasp the full context of the prompt, causing them to generate code that doesn't align with the intended use
Additionally, there isn’t clear data out there about what types of code generation errors are most typical, and if different LLMs make the same errors.
Luckily, and thanks to research teams at University of Illinois, University of Alberta, Purdue University, The University of Tokyo, and other institutions, we have some empirical evidence on when LLMs get it wrong generating code from their paper, Where Do Large Language Models Fail When Generating Code?
We’ll look at the most popular types of errors when using LLMs for code generation, how different models face different challenges, and what you can do to generate better, more complete code with LLMs.
Experiment setup
To better understand when using LLMs for code generation falls short, the researchers tested multiple models on many code generation tasks and analyzed the errors using the HumanEval dataset.
The dataset consists of a variety of Python programming tasks designed to test the models’ code generation capabilities. It is widely used. Here’s an example task:
# [Task 146] Return the number of elements in the array that are # greater than 10 and both first and last digits are odd.
A total of 558 incorrect code snippets were identified by running the generated code against the provided unit tests.
The errors were analyzed along two dimensions – semantics and syntax:
- Semantic Errors: High-level logical mistakes, such as missing conditions or incorrect logical directions, that reflect the LLM's misunderstanding of task requirements.
- Syntactic Errors: Specific code errors, like incorrect function arguments or missing code blocks, that indicate issues in code structure and syntax.
Models Used:
- CodeGen-16B: An open-source model by Salesforce trained on a large dataset of Python code.
- InCoder-1.3B: Developed by Meta AI, this model uses a causal masking objective to generate code.
- GPT-3.5: No intro needed
- GPT-4: If GPT-3.5 had a much smarter sibling
- SantaCoder: Part of the BigCode project, trained on a diverse dataset of programming languages.
- StarCoder: Another BigCode project model, trained on a comprehensive dataset including multiple programming languages.
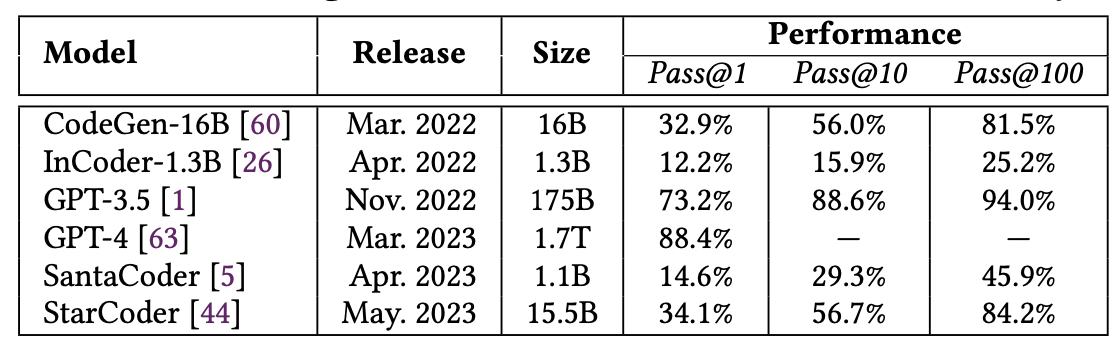
We'll dive deeper into results later, but here are the performances for each of the models.
Dataset: HumanEval
HumanEval is a dataset specifically designed to benchmark LLMs’ ability to generate correct code. It comprises 164 hand-written Python programming tasks, each with unit tests.
The tasks cover various aspects of programming (logic, algorithms, etc.).
Methodology
Researchers used the following steps to conduct their analysis:
- Data Collection: Each LLM was prompted with tasks from the HumanEval dataset, and the generated code was collected.
- Error Identification: Incorrect code snippets were identified by running the generated code against the provided unit tests.
- Error Classification: The errors were classified into semantic and syntactic categories
- Statistical Analysis: The correlation between different error characteristics and factors like prompt length, code length, and test-pass rate was analyzed.
Experiment results
With the setup out of the way, let’s jump right into results.
Error types
The study categorized errors into semantic and syntactic types. We’ll start with the semantic errors.
Semantic Errors: High-level, logical mistakes that reflect the model's misunderstanding of task requirements. These include:
- Condition Errors: Missing or incorrect conditions in the code.
- Constant Value Errors: Incorrect constant values set in function arguments, assignments, or other parts of the code.
- Reference Errors: Incorrect references to variables or functions, including undefined names or wrong methods/variables.
- Operation/Calculation Errors: Mistakes in mathematical or logical operations.
- Garbage Code: Unnecessary code parts that do not contribute to the intended functionality, such as meaningless snippets, only comments, or wrong logical direction.
- Incomplete Code/Missing Steps: Absence of crucial steps needed to achieve the task.
- Memory Errors: Infinite loops or recursions that never terminate.
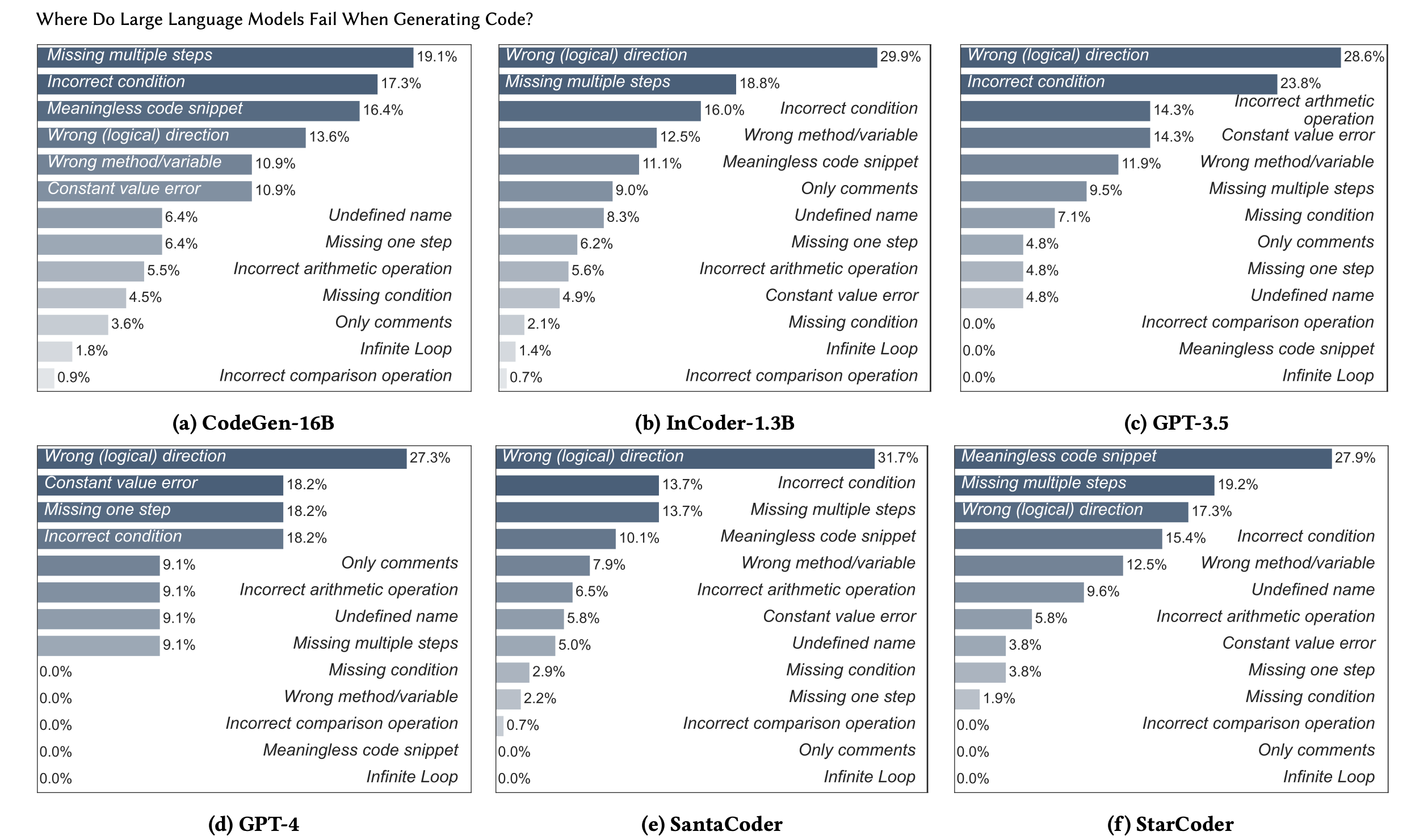
Takeaways
- All LLMs share issues like incorrect conditions and wrong logical directions, indicating they struggle with handling complex logic conditions regardless of model size and capability.
- Smaller models (InCoder and CodeGen) were more likely to generate meaningless code and/or code that missed multiple steps.
- Larger models (GPT-3.5 and GPT-4) tended to make more constant value errors and arithmetic operation errors.
- Overall, GPT-4 performed the best, exhibiting only 7 of the 13 semantic characteristics, while the other, smaller models exhibited all or most of the error types. More parameters, less problems
Interestingly, even for the same task, different LLMs produced buggy code with varying error types.
Given this information, if you're using LLMs for code generation, you could:
- Test specific prompt engineering methods to overcome the issues. We’ve written before about how different models require different prompting approaches.
- Fine-tune one of these models based on where it falls short to fill in the gaps.
- Use an ensemble of models for different tasks in your product.
Let’s move onto the Syntactic errors
Syntactic Errors: Specific code errors that indicate issues in the structure and syntax of the generated code. These include:
- Conditional Error: Errors within 'if' statements, causing incorrect code behavior.
- Loop Error: Mistakes in 'for' or 'while' loops (incorrect boundaries or mismanaged variables).
- Return Error: Errors in return statements, returning wrong or incorrectly formatted values.
- Method Call Error: Errors in function calls, including incorrect function names, wrong arguments, or incorrect method call targets.
- Assignment Error: Errors in assignment statements
- Import Error: Errors in import statements.
- Code Block Error: Multiple statements incorrectly generated or omitted
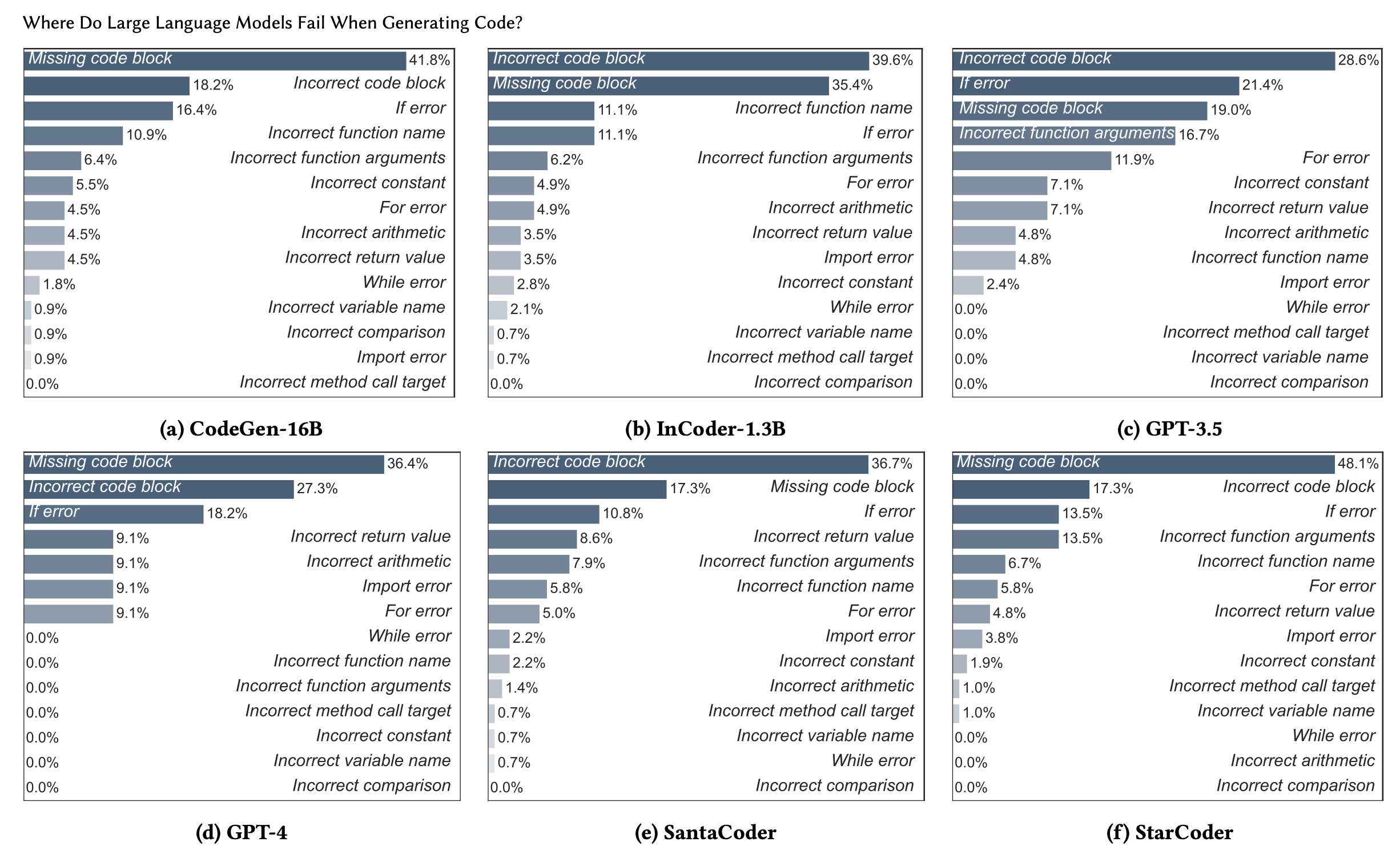
Takeaways
- The distribution of errors is relatively similar across all models.
- Across all models, the top three error locations are entire code blocks and 'if' statements. This suggests that many code generation errors are significant and require a lot of work to fix.
- GPT-4’s errors are more well-contained in a smaller number of categories. This suggests that GPT-4 has fewer and more predictable areas of difficulty compared to other models.
- GPT-4 didn’t produce any errors in multiple categories (see chart where the value is 0%).
- CodeGen-16B and InCoder-1.3B frequently have errors with incorrect function names. GPT-3.5, SantaCoder, and StarCoder more often encounter incorrect function arguments.
- More than 40% of the syntactic errors made by all six LLMs could be grouped into missing code block and incorrect code block.
Repair Effort
Errors are one thing, but their severity and how long they take to fix is another.
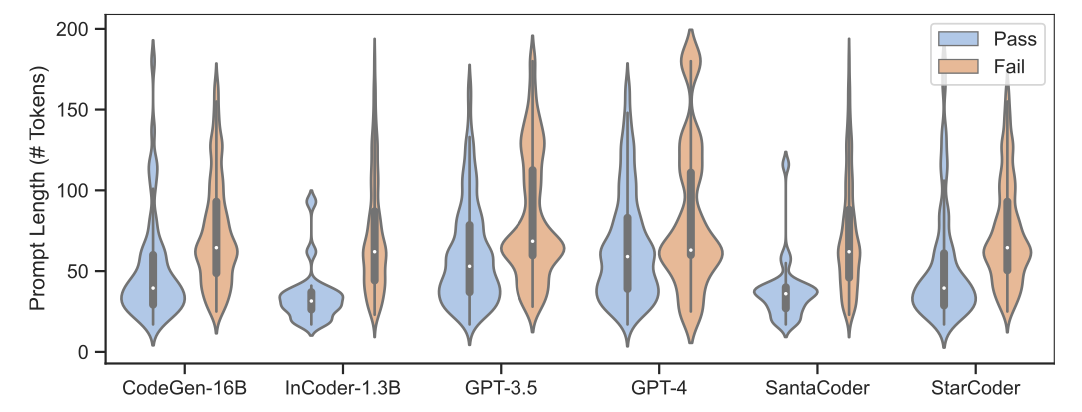
To figure out how “wrong” the generated code was, the researchers leveraged two metrics: Jaccard similarity and Levenshtein distance.
Jaccard Similarity: Treats code as a set of tokens (for more info on tokens, check out our article here), and measures similarity by the overlap between two snippets. Lower Jaccard similarity indicates fewer common tokens between the generated code and the ground truth, which means the code is less accurate.
Levenshtein Distance: Measures the minimum number of edits (insertions, deletions, or substitutions) needed to correct incorrect code snippets, providing a direct measure of the repair effort. A lower Levenshtein distance indicates that fewer changes are needed to correct the code, which means the generated code is closer to the ground truth.
Below is a graph with the results for each metric.
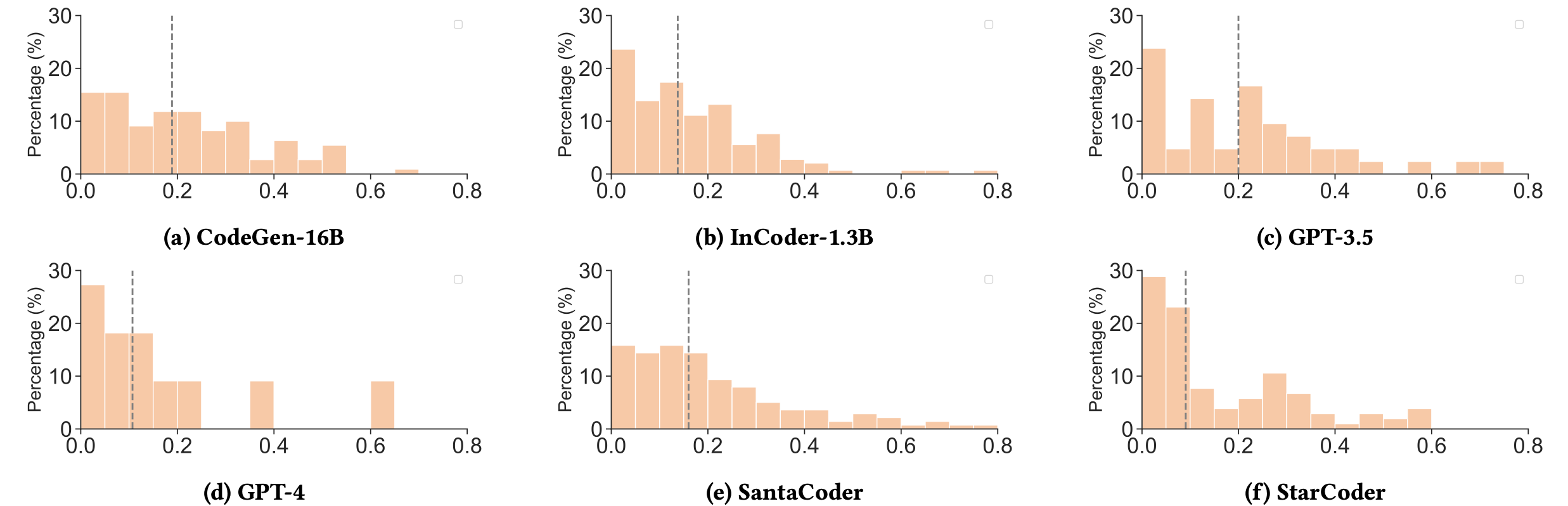
As you can see, the LLM-generated code is often very different from the ground truth. These aren’t just minor errors.
While GPT-3.5 and GPT-4 had the highest overall accuracy, they had the largest deviations when generating incorrect code. They had the highest median Levenshtein distances.
So, the GPT models are more accurate, but when they get it wrong, they get it really wrong.
Not every mistake is equal. A syntactical error of a colon versus a semi-colon is much different than an entire code block being incorrect. The researchers broke down the errors into three categories based on the effort required to fix them:
- Single-line errors
- Single-hunk errors
- Multi-hunk errors
A “hunk” refers to several lines of code.
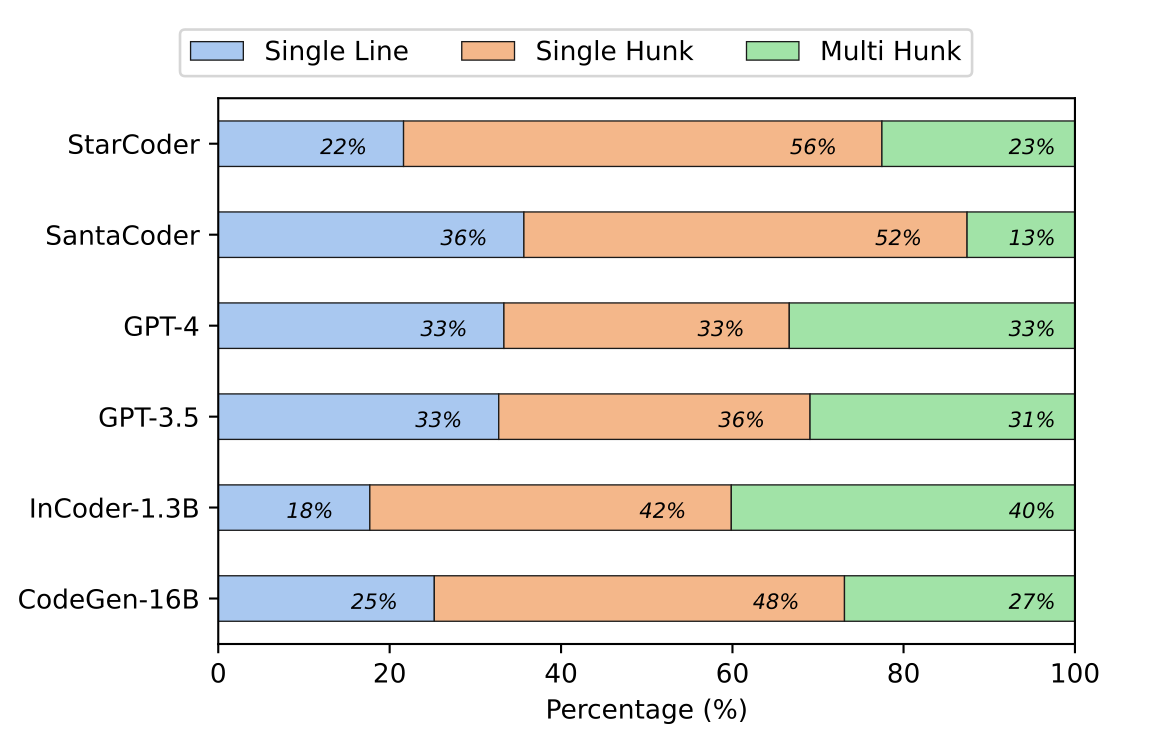
As you can see, a majority of the errors were single-hunk or multi-hunk, which require a lot of work to repair.
Here’s the main takeaway: When the LLMs generated incorrect code, they tended to generate code that deviated significantly from the ground truth code.
Does Prompt Length Affect Code Quality?
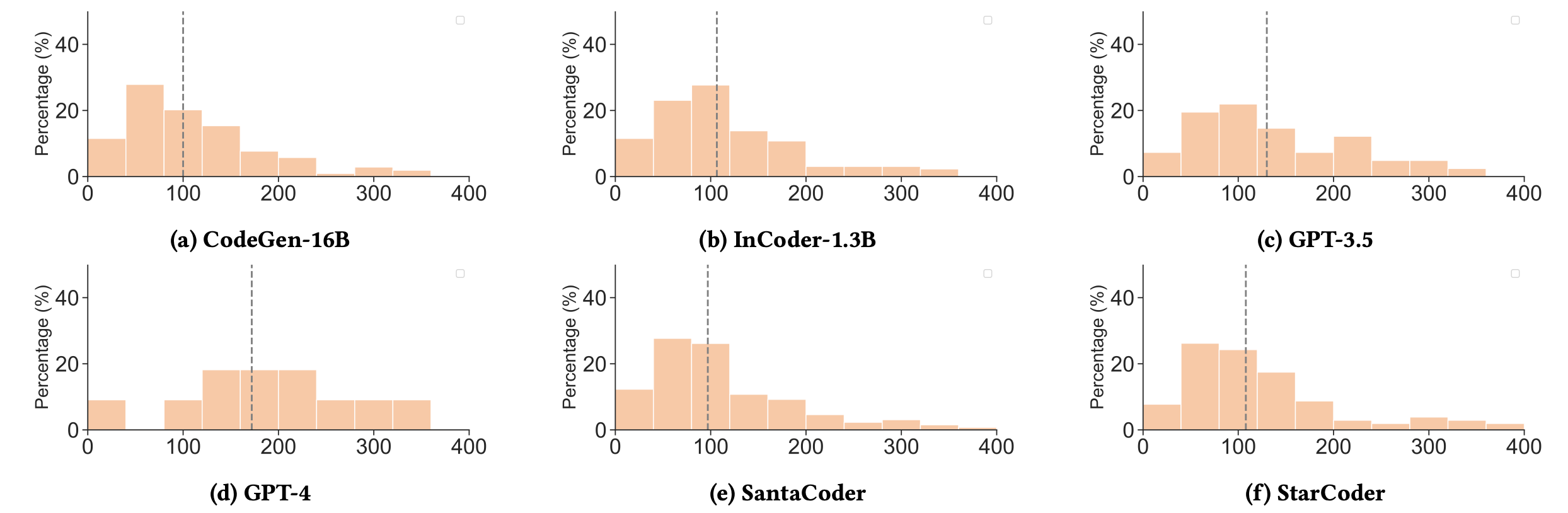
Next up was my favorite part of the study. The researchers analyzed the relationship between prompt length and the model’s ability to generate correct code.
The average prompt length in HumanEval is approximately 67 words, and 40% of the prompts include 50 words or less.
Takeaways
Effect of Prompt Length:
- Prompts with fewer than 50 words generally led to better performance across all models.
- Prompts exceeding 150 words significantly increased the likelihood of errors.
Types of Errors in Long Prompts:
- Garbage Code: A large portion (64%) of errors in long prompts resulted in garbage code, where the generated code included unnecessary parts that didn't contribute to solving the task.
- Meaningless Code Snippets: Around 37.5% of errors in long prompts were "meaningless snippets," (syntactically correct, but fail to address the task requirements)
- Only Comments: Some long prompts resulted in code that consisted only of comments
- Wrong Logical Direction: Long prompts often caused the models to generate code that deviated significantly from the intended task logic
Prompt engineering implications
- Longer prompts ≠ better prompts.
- Test using concise and focused prompts (a best practice anyway)
- Providing clear and specific task descriptions without unnecessary details can reduce the occurrence of garbage code and other errors.
- This doesn’t mean all long prompts are bad! Longer prompts can be necessary, especially when doing things like Few Shot Prompting
Code Generation with Reasoning Models
Newer models like o1-preview and o1-mini from OpenAI have incorporated chain of thought prompting automatically via inference-time reasoning tokens. The way you prompt these models to generate code is very different from non-reasoning models like gpt-4o.
Luckily there has been a flurry of papers recently about using reasoning models for code generation. We'll specifically be leveraging data from Do Advanced Language Models Eliminate the Need for Prompt Engineering in Software Engineering?
Effectiveness of built-in reasoning
Since reasoning models like o1-mini, have reasoning built into their inference-time, traditional CoT prompts (e.g., "think step-by-step") offer limited benefits and can sometimes even reduce performance.
The researchers tested o1-mini across three code related tasks: Generation, translation, and summarization.
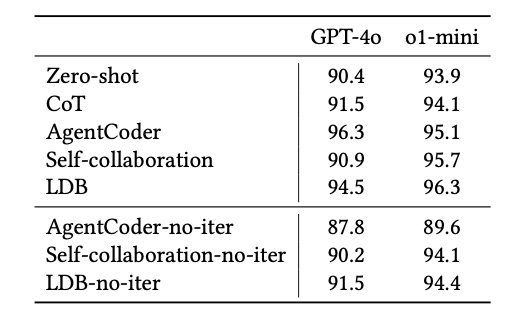
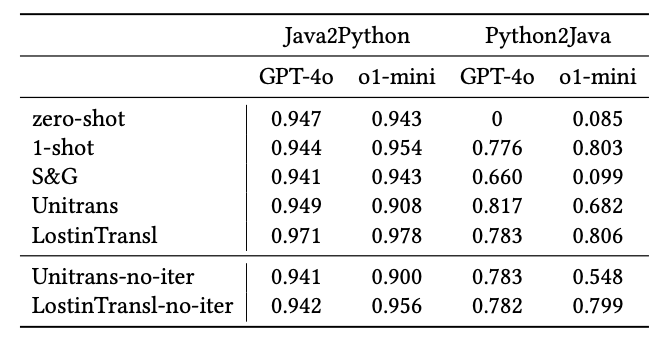
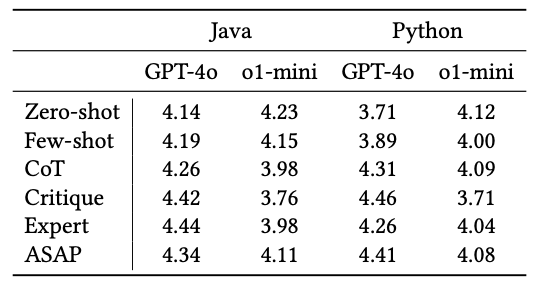
Here are the key takeaways:
- Prompt engineering methods had minimal impact on o1-mini’s performance and, in some cases, even reduced it.
- GPT-4o showed more significant performance improvements from prompt engineering techniques compared to o1-mini.
- With well-crafted prompts, GPT-4o was able to match the performance level of o1-mini in certain tasks.
For more info on general best practices about prompt engineering with reasoning models, check out our guide here: Prompt Engineering with Reasoning Models.
Wrapping up
If you're using LLMs for code generation, there are a lot of potential points of failure along the way. Hopefully this guide helps you get out in front of a few of them. Precise and clear prompt engineering is always important, but it might be even more important when using LLMs to generate code. As we always say, it's an iterative process when working with LLMs!





