
Most users leave the parameters set to their default when working with OpenAI’s models like GPT-3.5 Turbo and GPT-4. Knowing how you can leverage these parameters to influence your outputs can help you upgrade your prompts.
In this article, we’ll dive into the key parameters for OpenAI’s core models, GPT 3.5-Turbo and GPT-4, explaining what they do and how they influence the model's behavior.
Whether you're developing an AI application or just curious about how AI works, this guide will give you a clearer picture of the power behind these parameters, and how you can leverage them to write better prompts.
Temperature
What is it?
Temperature influences how deterministic the response from the model will be. The lower the temperature, the more deterministic. The higher the Temperature, the more creative and chaotic the response will be.
How does it actually work?
Large Language models are prediction machines. They generate responses by predicting which token is most likely to come next (for more on how tokenization works, check out our article: Tokens and Tokenization: Understanding Cost, Speed, and Limits with OpenAI's APIs.).
Temperature adjusts the probability distribution from which the model’s next token is drawn. The lower the Temperature, the higher chance that the model will go with the most probable next token. The higher the Temperature, the greater the probability that the model will select a token that is not the most probable.
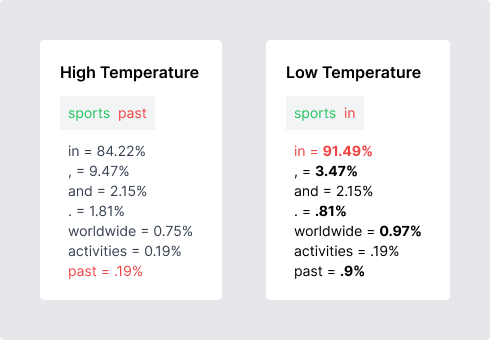
As you decrease the Temperature, you lower the chances of selecting tokens with less probability, and increase the likelihood that the model will choice a more probable token.
Examples

As you can see above, with a low Temperature, we get a relatively basic response.

When we turn up the Temperature we see the model responds more creatively. The red tokens represent low token probabilities.
Max Tokens
What is it?
The Max Tokens parameter determines the maximum length of the response generated by the model.
How does it work?
When you set the Max Tokens parameter, the model will generate a response that contains no more than the number of tokens selected.
Example
I ran the same prompt, “Tell me a story about a startup founder” but with 2 different Max Tokens values. 120 on the left and 270 on the right.
As you can see, when you give the model more tokens to work with, it tends to go into more detail. This harkens back to a key tenet of prompt engineering, you need to give the model room to think.
It is important to keep in mind that the more tokens used, the higher the cost of the request (shown below, the second response cost about twice as much). That’s why it is good to test different Max Token values to find a good balance between detailed responses and cost-efficiency.
Additionally, your specific use case will determine where you should set this value. If you need shorter responses, keep your Max Tokens low. If you need longer responses, keep it higher.

You'll notice both of the stories seem to stop mid-sentence. This is an potential issue you when you constrain models via Max Tokens.
Top P
What is it?
Top P, similarly to Temperature, influences the creativity of the model’s responses. It is also referred to as nucleus sampling.
How does it work?
Top P is a little technical. It works by selecting the smallest set of tokens whose cumulative probability exceeds the P value.
If Top P is set to .9, the model will consider only the smallest set of tokens whose combined probability exceeds .9 for genereating the next token. This means that less probable tokens will be excluded from consideration, leading to a more deterministic response.
The key difference between Temperature and Top P is how they influence the selection of less probable tokens. A lower Temperature reduces the probability of less likely tokens but doesn't eliminate them entirely—they still have a chance to appear. On the other hand, a lower Top P narrows down the set of plausible next words by eliminating a portion of less likely tokens from consideration entirely.
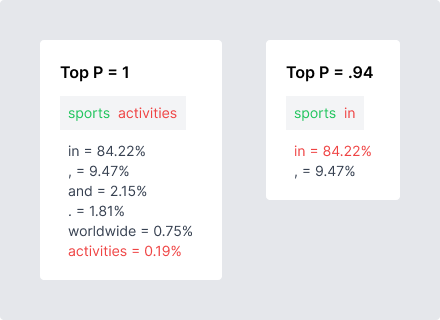
It’s really important to note that you should not use both simultaneously. OpenAI recommends only using one at a time. If you’re using Top P, make sure Temperature is set to 1, and vice versa.
Example
If we have a prompt, “the sun is”, and Top P is set to a high value, the model might generate a diverse set of possible completions like “hot”, “warm”, “shining”, or “a star”.
If Top P was a lower value, the possible completions would be more focused and would exclude the more creative outcomes like “a star”.
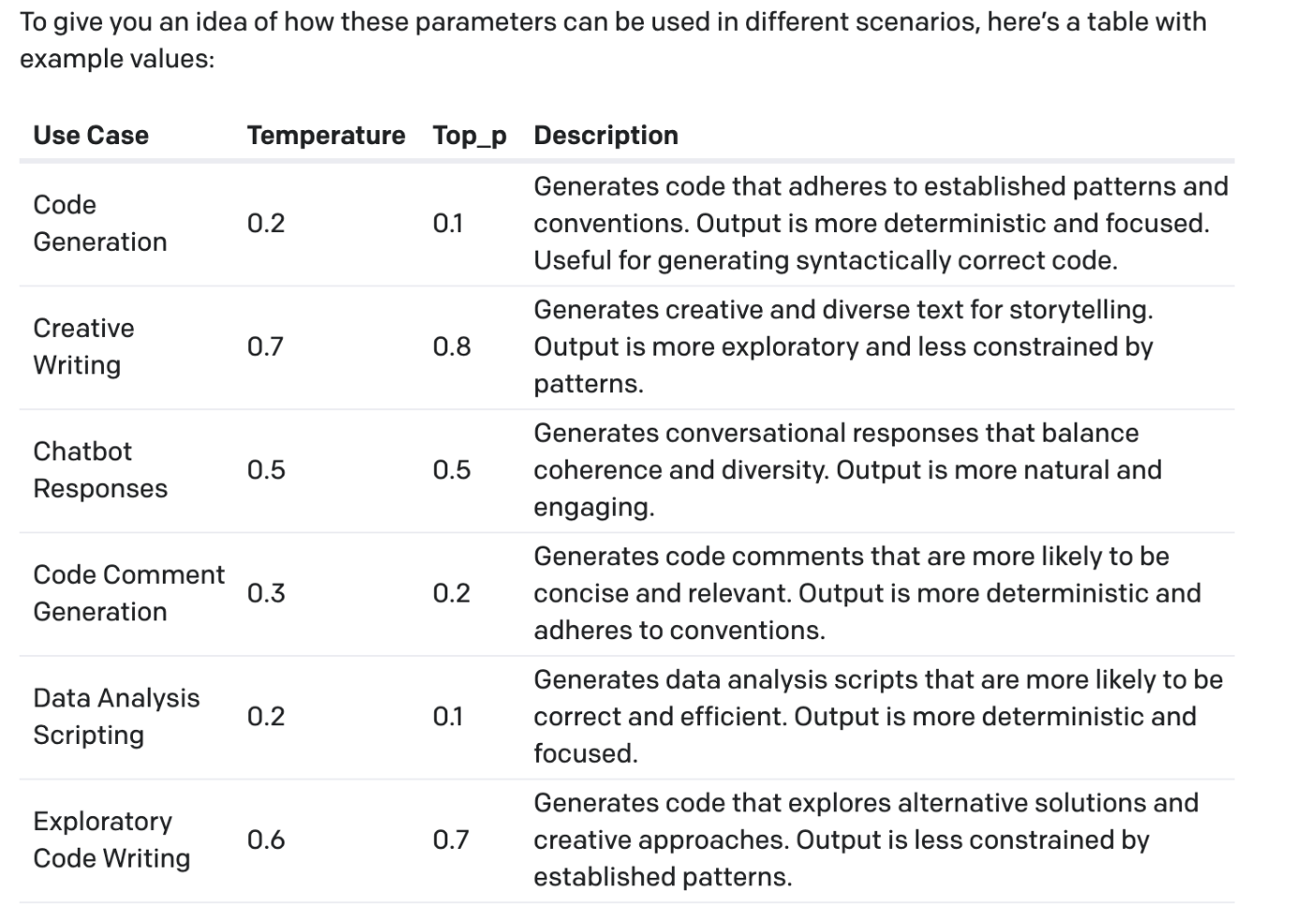
Recommendations on Temperature and Top P
Below is a cheat sheet for Temperature and Top P values based on use case.
Frequency Penalty and Presence Penalty
What are they?
Frequency Penalty and Presence Penalty are parameters that enable you to control the repetition of words or topics in the generated text.
How do they work?
Frequency Penalty helps prevent word repetitions by reducing the chance of a word being selected if it has already been used. The higher the frequency penalty, the less likely the model is to repeat the same words in its output.
Presence Penalty helps prevent the same topics from being repeated by penalizing a word if it exists in the completion already, even just once.
Example
Let’s use the following prompt as our example: “PromptHub makes it easy test __ “
If we’ve already filled in that blank with “prompts” many times in the past in the same completion, a high frequency penalty would make “prompts” less likely to be chosen again. This helps increase variety in word selection and avoid repetition.
On the other hand, a high Presence Penalty would discourage the model from using "prompts" again even if it had been used only once before in the completion.
Most users tend to leave these parameters at their default values of 0. This allows the model to do what it does best, and generate responses based on its training data without constraints.
Additionally, make note that messing around with these parameters can have subtle and unpredictable effects. I would say that unless you have a very strong reason to change them, leave them at their default values.
Best Of
What is it?
Best of allows you to select a certain number of responses you’d like the model to generate on the serverside to pick the best from.
How does it work?
The number you select is the number of response variants the model will produce. It will then select only one and return that to you.
It makes its decision based on an internal, proprietary, scoring mechanism.
Since the scoring mechanism isn’t public, it’s important to keep in mind that what the model determines as “best” might not align with your use case. Additionally, the higher the number, the more tokens that will get used. Keep this in mind if you decide to test out this parameter!
Inject Start Text and Inject Restart Text
What are they?
These parameters automatically insert specific text at the start and end of the model’s response. They are only available in the OpenAI playground.
How do they work?
Generally, these parameters have been used to help make completion models feel like chat models by making responses feel conversational.
- Inject Start Text: The specified text will be at the start of the model's response. For example, if you set the Injection Start Text as “AI:” then the response would be
"AI: RESPONSE FROM MODEL" - Inject Restart Text: The inject restart text gets appended to the end of the model’s response. For example, if you set the Injection Restart Text as "User:", then the response would be:
"AI RESPONSE
Use"r:
Conclusion
Experimenting with parameters is something we recommend to ny person building on top of these models. Not leveraging these parameters is like not considering a whole section of your tool box, you might just find that certain configurations help you get better results.
In PromptHub, you can easily test these parameters on the same prompt and compare the outputs side by side. This makes it really easy to see how outputs change based on parameter selection, including important factors like tokens, cost, and latency.
These parameters are continually changing as well, so it is good to stay on top of this.





