
If you’ve ever used ChatGPT and felt that, once it takes a wrong turn the conversation becomes unrecoverable, you’re not alone and now there is research to back it up.
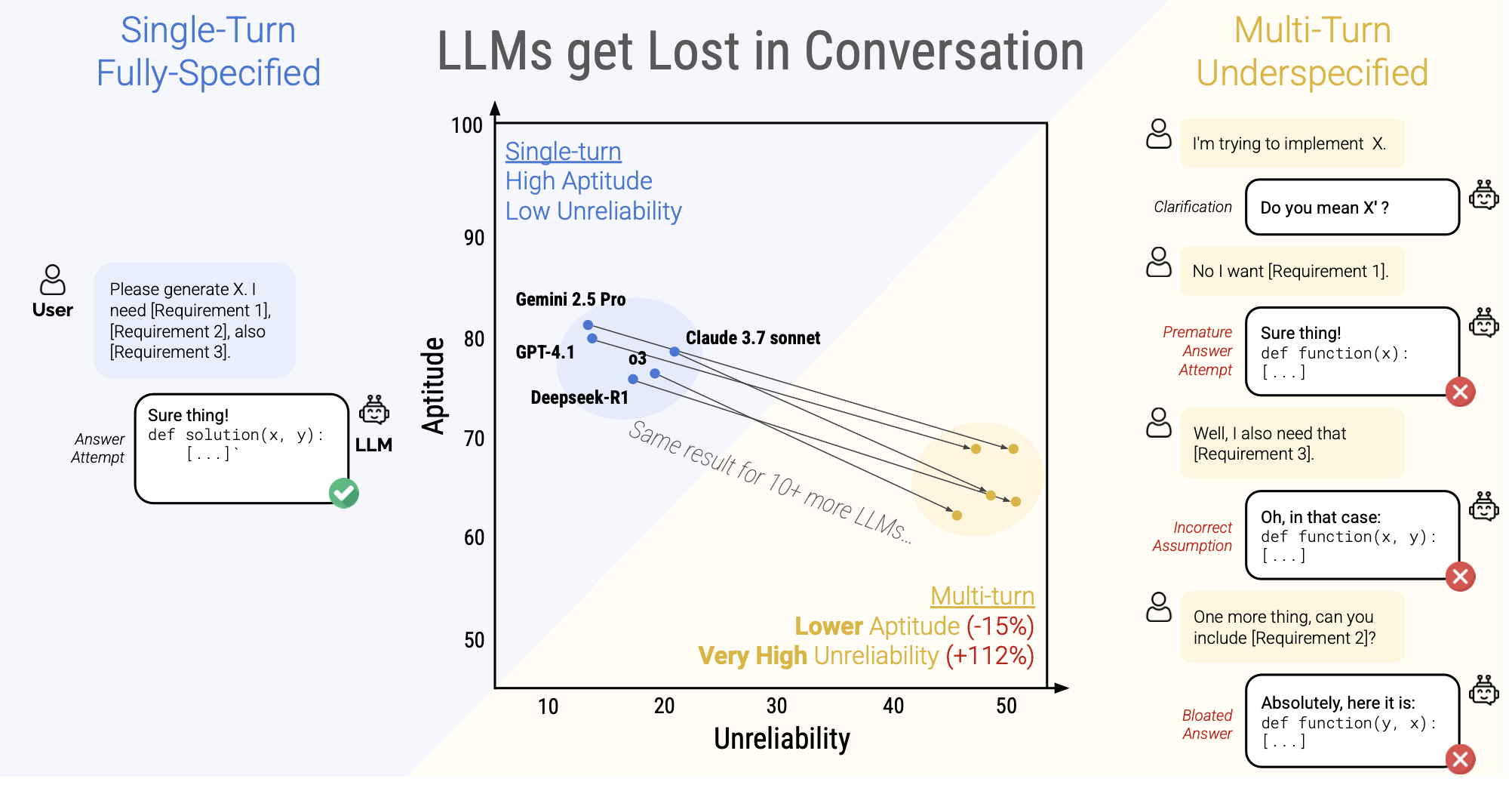
The paper LLMs GET LOST IN MULTI-TURN CONVERSATION took single-prompt instructions and broke them into shards to see how LLMs would perform when given information over multiple messages, rather than all at once. In some cases, even on flagship models like Gemini 2.5 Pro, performance dropped by 40%.
The TL;DR:
- 39% performance drop on average when tasks unfold over multiple messages versus a single, fully specified prompt upfront
- Unreliability more than doubles
- Reasoning models performed just as poorly as non-reasoning models
This is really critical for both app developers and everyday AI users.
We'll dive into the experiments, why models fail in multi-turn conversations, and what you can do as a developer or user of AI apps.
Single-Turn benchmarks miss conversational complexity
Most popular benchmarks hand the model a fully specified task up front, in a single prompt. In that setup, the model sees every requirement in one go and then responds.
But real conversations and AI applications often don’t work that way. Usually users reveal information piece by piece and work with the model to clarify certain instructions. Think about ChatGPT, deep research, etc.
By not accounting for these types of use cases, benchmarks give a rosy overview of a model’s capabilities. This paper tests conversational style flows that are much more representative of common AI applications and use cases.
Experiment setup
To test conversational performance, the researchers took single-turn prompts from popular benchmarks and sliced each into a series of smaller “shards”. Each shard reveals just one piece of the full prompt.

These shards were generated via a four-step process, not just by cutting up the original full prompt:
- Segmentation: An LLM splits the full prompt into non-overlapping segments via a few-shot prompt.
- Rephrasing: Each segment is rephrased and reordered into conversational “shards”.
- Verification: The original and sharded instructions are tested side-by-side, to confirm no information loss.
- Manual Review: Authors do a final, manual, review.

At each turn, the model sees only the next shard, responds, and may attempt an answer or ask for clarification.
Key components of the setup:
- Tasks & models: Six task types (code generation, SQL queries, math problems, API-style Actions, data-to-text, and long-document summarization) across 15+ LLMs.
- Scale: Over 200,000 synthetic conversations.
- Metrics:
- Performance (P): Overall average accuracy
- Aptitude: The 90th-percentile score
- Unreliability (U₉₀₋₁₀): The difference between the 90th- and 10th-percentile scores, capturing the range of best to worst.
- Reliability (R): Represents the model’s consistency by quantifying how tightly clustered its performance is around the average. Calculated as 100 – U₉₀₋₁₀.
Methods tested

Evaluation Settings
- FULL – The model sees the original, fully specified instruction in one prompt (single-turn).
- SHARDED – The instruction is split into N “shards,” revealed one per turn.
- CONCAT – All shards are concatenated into a single prompt. Differs from FULL in that the shards are less specific.
- RECAP – Same as SHARDED, but on the final turn all previous shards are sent. In this case, there is a message history (unlike in CONCAT).
- SNOWBALL – Like SHARDED, but at each turn all prior shards are prepended before revealing the next one.
Results
Let’s look at some data:

- Universal drop: Nearly every model’s accuracy falls in SHARDED vs. FULL, with an average degradation of 39%.
- CONCAT to the rescue: CONCAT performance averages 95.1% of the FULL baseline, which shows that information loss from sharding isn’t the reason why performance drops.
- Smaller models perform slightly worse: Llama3.1-8B-Instruct, OLMo-2-13B, and Claude 3 Haiku show larger CONCAT hits (86–92% of FULL).
- Flagship models fail too: Claude 3.7 Sonnet, Gemini 2.5 Pro, and GPT-4.1 lose 30–40% in SHARDED mode, just as much as smaller models.
- Reasoning tokens don’t save the day: o3 and Deepseek-R1 degrade just like their non-reasoning counterparts. Their longer (~33%) responses give more room for incorrect assumptions.
Next up, the researchers tested SNOWBALL and RECAP methods, on GPT-4o, and GPT-4o-mini to see how much some level of refreshing the model's memory could recover lost performance.
As a reminder, here is how each method works:
RECAP: After the usual multi-turn shards, add one final user turn that repeats all previous shards before the model’s last attempt.
SNOWBALL: At each turn, prepend all prior shards before revealing the next one, giving the model continuous redundancy.

- RECAP recovers to ~66–77%, up from ~50% on SHARDED
- SNOWBALL adds ~12–15 percentage points over SHARDED, but underperforms compared to RECAP and trails FULL by ~15–20 points.
Why models fail at multi-turn conversations
In general, the researchers determined four major failure reasons.
1. Premature answer attempts
Across every model, accuracy increases when the first answer attempt happens further in the conversation.

- First 20 % of turns: 30.9% average score
- Last 20 % of turns: 64.4% average score
Models that attempt to answer too soon tend to lock in mistakes. The longer they waited, and as they got more information, the better their chance to put it all together and answer correctly.
2. Verbosity inflation (answer bloat)
Throughout the multi-turn conversation, the LLM will generate incorrect answer attempts and related assumptions. As the user reveals more information, the model doesn’t always invalidate previous incorrect assumptions.
This leads to longer final solutions, aka, “answer bloat”.

- Final answers grow well beyond single-turn baselines (Code climbs from ~700 chars to over 1,400).
- Assumptions stick: New shards rarely invalidate prior guesses, so each response layers on more content.
- Result: Bloated, error-ridden outputs
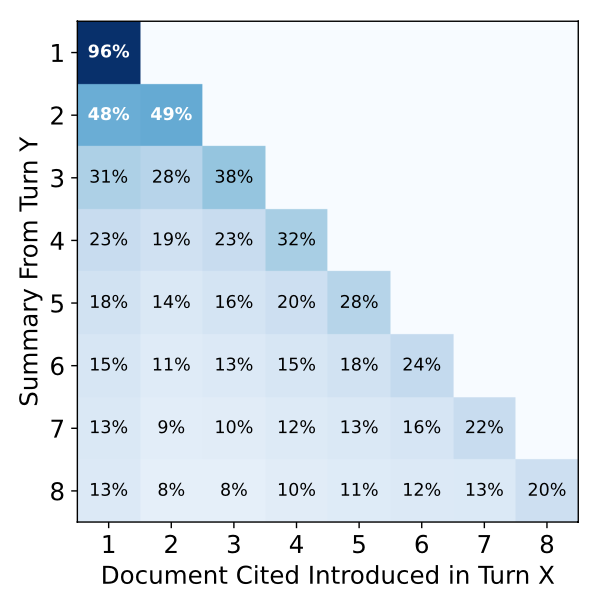
3. Lost-in-Middle
It is well-known that models tend to pay most attention to what they see first and last in a given context window, often skipping over content in the middle.
Below is an analysis of how often models cite each document in their running summaries during sharded simulations. At every turn, the LLM produces an updated summary (y-axis) that may include citations from any documents revealed so far.
4. Over-Verbosity Harms Performance
As response length increases, average accuracy declines (not by a ton, but not a little):

Longer model outputs risk veering off course by introducing extra assumptions.
Advice for agent and app builders
If you’re building LLM-based applications with multi-turn conversations, these strategies can help mitigate performance degradation:
- Test multi-turn flows: Explicitly include multi-turn scenarios in your test cases and evaluation suites.
- Consolidate before generation: When you’re ready to generate an output, batch all collected user context into one prompt and send it as a fresh LLM call instead of continuing to drip information.
Implications for everyday AI users
- If your chat goes off the rails, start fresh. Rather than wrestling with a derailed conversation, start a new chat and try to give as much context as possible up front.
- Consolidate mid-chat. Ask the model “Can you summarize everything I’ve told you so far?” then paste that summary into a fresh session to reset context.
- Keep prompts focused and concise. Short, pointed messages can help the model stay on track. Try to avoid rambling instructions spread over multiple back-and-forths, which create more chances for incorrect assumptions.
Conclusion
This was an eye-opener. So many of the AI applications out there today are multi-turn, but I’m very confident in saying that multi-turn conversations are not thought of enough when doing testing. Even top LLMs can get lost after just two back-and-forths (!!), resulting in accuracy declines of 39%. Whether you’re testing in PromptHub or some other tool, don’t sleep on having multi-turn test cases as a core part of your testing and eval workflow.




