
The first line in the Claude 4.5 announcement from Anthropic is “Claude Sonnet 4.5 is the best coding model in the world.” In many ways, it lives up to that promise, but falls short in others.
If I had to choose, I would still lean towards GPT-5 for coding, but Claude 4.5 is still very performant and I could see myself switching back and forth as I use it more.
Aside from the model release, there are a bunch of other goodies in this launch, like new features such as memory, context editing, token-aware conversations, and a pretty robust Agent SDK (the same SDK that powers Claude Code).
The Model
Coding
The headline feature of Sonnet 4.5 is its raw performance at coding, using a computer, and agentic tasks. Anthropic positions Sonnet 4.5 as the best coding model available today and benchmark results back that up. It outperforms previous Claude versions (and most competitors) on tasks like code generation, debugging, and multi-file reasoning. Let's look at some benchmarks.
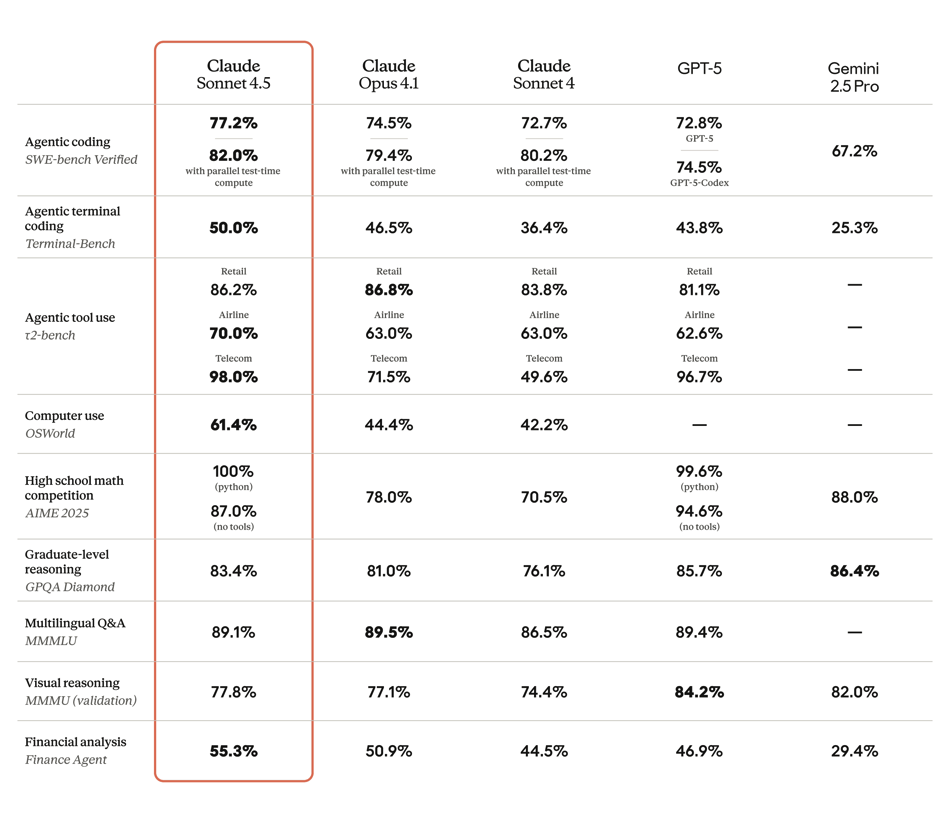
There was a lot of emphasis on better reasoning and handling long-running tasks. They note that it can maintain focus for more than 30 hours on complex tasks (SWE-Bench) across large codebases.
The quote below is the only place I found substantive information backing up the 30+ hour claim.

Alignment
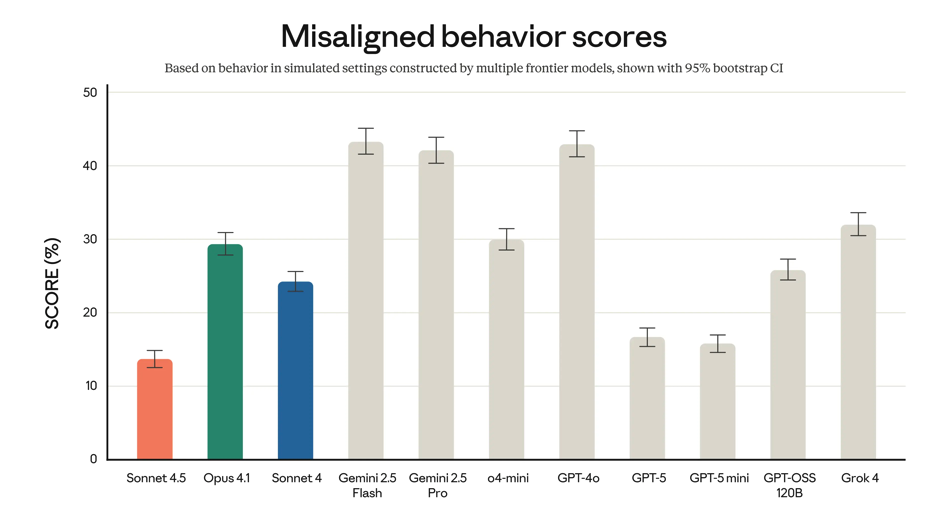
It is supposed to be the most aligned frontier model they’ve ever released. Key point, “they’ve ever released”, not “ever released”.
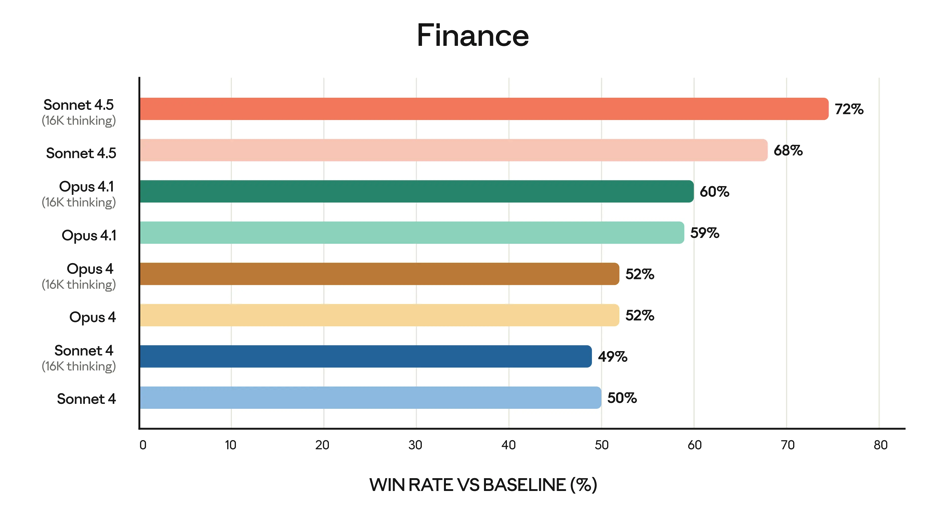
Considering Anthropic is supposed to be the safety AI lab, it’s a little embarrassing that they’ve been getting beat by OpenAI. GRAPHS
Additionally, it should be less sycophantic, deceptive, and power-seeking — and it should encourage delusional thinking less.
Computer use
Computer use made a huge jump here. Computer use is still pretty far from working reliably in production, but this is a meaningful step. On OSWorld, a benchmark that tests models on real-world computer tasks, Sonnet 4.5 leads at 61.4%. Just four months ago, Sonnet 4 held the lead at 42.2%. GRAPHS
Prompt injections
Claude 4.5 should be better at defending against prompt injection attacks when Claude is using a computer. Prompt injections are always an issue, especially when it comes to computer use since prompts can be embedded anywhere in a site’s source code. Here is an example of a prompt injection embedded into a website: Understanding prompt injections and what you can do about them.
Next up are the most interesting non-model aspects of this launch: built-in tools for memory and context management (sort of) via the API.
Persistent Memory
Straight from the announcement:
We've added a new context editing feature and memory tool to the Claude API that lets agents run even longer and handle even greater complexity.
How Memory Works
The memory tool (example below) lets Claude store and retrieve information across conversations through external files. The model chooses when to create, read, update, and delete files that persist across conversations. This allows it to build up context over time in a file directory it can access when necessary, rather than keeping everything in the context window.
As with all of Claude’s API features, to enable the memory tool you need to include the following in your header: context-management-2025-06-27.
You’ll also need to add the memory tool to your request, and implement the client-side handlers for all the memory operations (create, read, update, etc).
When you enable memory, Claude will automatically check its memory (the file directory) before generating a response.
Claude calls the tool, and your app executes those operations locally (client-side).
{
"type": "tool_use",
"id": "toolu_01C4D5E6F7G8H9I0J1K2L3M4",
"name": "memory",
"input": {
"command": "view",
"path": "/memories"
}
}
Example request
{
"model": "claude-sonnet-4-5-20250929",
"max_tokens": 1024,
"system": [
{
"type": "text",
"text": "You are a helpful assistant."
}
],
"messages": [
{"role": "user",
"content": "Respond to cs ticket. ticket #fjeu299"}
],
"tools": [{
"type": "memory_20250818",
"name": "memory"
}]
}
Example response
{
"id": "msg_01J7ticyNg5wGKFfDa6ezr4Y",
"type": "message",
"role": "assistant",
"model": "claude-sonnet-4-5-20250929",
"content": [
{
"type": "text",
"text":
"I'll help you respond to this..
Let me first check my memory for any relevant information or templates."
},
{
"type": "tool_use",
"id": "toolu_01RfzTBvnUsDyVa2Fddn6k72",
"name": "memory",
"input": {
"command": "view",
"path": "/memories"
}
}
],
"stop_reason": "tool_use",
"stop_sequence": null,
"usage": {
"input_tokens": 1598,
"cache_creation_input_tokens": 0,
"cache_read_input_tokens": 0,
"cache_creation": {
"ephemeral_5m_input_tokens": 0,
"ephemeral_1h_input_tokens": 0
},
"output_tokens": 98,
"service_tier": "standard"
},
"context_management": {
"applied_edits": []
}
}
By default, it will always say something like “let me check my memory first,” because Claude adds this to your system prompt when the memory tool is enabled:
IMPORTANT: ALWAYS VIEW YOUR MEMORY DIRECTORY BEFORE DOING ANYTHING ELSE.MEMORY PROTOCOL:
1. Use the `view` command of your `memory` tool to check for earlier progress.
2. ... (work on the task) ...
- As you make progress, record status / progress / thoughts etc in your memory.
ASSUME INTERRUPTION: Your context window might be reset at any moment, so you risk losing any progress that is not recorded in your memory directory.
You can override this by including some instructions in the prompt so that the model still uses the tool but doesn’t announce it each time.
Memory currently only works for:
Why It Matters
First-party support for memory is a nice-to-have from Anthropic (it’s also available via their Agents SDK), especially when building agents or chat applications where a user has many conversations.
It’s a simple implementation, which is nice. Essentially we just tell the model to write things down in a file when it thinks it should and to read it when it thinks it should.
Memory allows developers to create user experiences that feel smoother and smarter, with fewer situations where users feel frustrated repeating themselves, and more cases where the model remembers key details you might have forgotten
Context Editing
Currently, the context editing tool is limited to clearing tool results when the conversation context grows past the threshold you set. The API will automatically clear the oldest tool result and replace it with a placeholder to let Claude know the tool was removed.
By default, only the tool results are cleared, but you can also clear the tool calls and parameters by setting clear_tool_inputs to true.

One thing to note is that context editing invalidates cached prompt prefixes, because clearing content modifies the structure of the cached prompt.
As a refresher, a prompt cache can only be hit if it exactly matches the previous prompt prefix, even just a single character difference will throw things off.
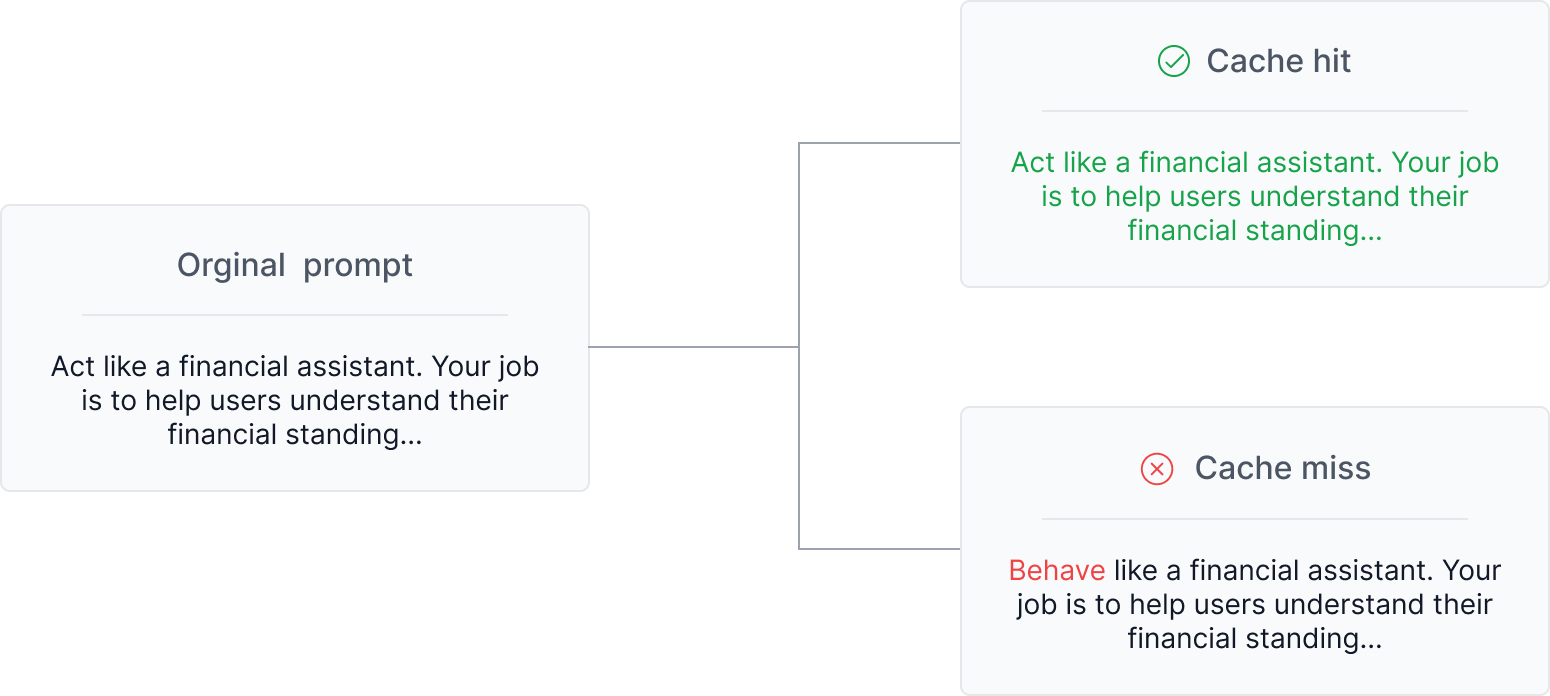
More info on prompt caching here: Prompt Caching with OpenAI, Anthropic, and Google Models
So if you’re going to clear tool call tokens, make sure it’s worth it — and clear as many as you think is reasonable. Future requests made after tool call tokens are removed can be cached and reused.
Configuration options
trigger– Default: 100,000 input tokens- Sets the point at which context editing activates. When the prompt exceeds this threshold, clearing begins. You can define this in either
input_tokensortool_uses. keep– Default: 3 tool uses- Determines how many recent tool use/result pairs are retained after clearing occurs. The oldest interactions are removed first, preserving the most recent ones.
clear_at_least– Default: None- Ensures a minimum number of tokens are cleared each time context editing runs. If the API cannot clear at least this amount, the strategy won’t be applied — helping you decide if clearing is worth breaking your prompt cache.
exclude_tools– Default: None- A list of tool names whose uses and results should never be cleared. Useful for protecting critical context from being removed.
clear_tool_inputs– Default: false- Controls whether tool call parameters are cleared along with their results. By default, only tool results are removed, keeping Claude’s original tool calls visible.
Examples
curl https://api.anthropic.com/v1/messages \
--header "x-api-key: $ANTHROPIC_API_KEY" \
--header "anthropic-version: 2023-06-01" \
--header "content-type: application/json" \
--header "anthropic-beta: context-management-2025-06-27" \
--data '{
"model": "claude-sonnet-4-5",
"max_tokens": 4096,
"messages": [
{
"role": "user",
"content": "Create a simple command line calculator app using Python"
}
],
"tools": [
{
"type": "text_editor_20250728",
"name": "str_replace_based_edit_tool",
"max_characters": 10000
},
{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 3
}
],
"context_management": {
"edits": [
{
"type": "clear_tool_uses_20250919",
"trigger": {
"type": "input_tokens",
"value": 30000
},
"keep": {
"type": "tool_uses",
"value": 3
},
"clear_at_least": {
"type": "input_tokens",
"value": 5000
},
"exclude_tools": ["web_search"]
}
]
}
}'
Here’s what each of those configuration options does in practice:
trigger– 30,000 input tokens:- Context editing will kick in once the prompt reaches 30,000 tokens, clearing out older tool results beyond that point.
keep– 3 tool uses:- Even after clearing starts, the system will always keep the three most recent tool use/result pairs so the model retains immediate context for ongoing tasks.
clear_at_least– 5,000 input tokens:- Each time context editing runs, it will only execute if it can clear at least 5,000 tokens. If less than that would be cleared, the strategy won’t run — helping you avoid unnecessary prompt cache breaks.
exclude_tools–["web_search"]:- Tool calls and results from
web_searchwill never be cleared, even if they’re old, ensuring critical search context remains available.
Example response
You’ll be able to see which edits were made via the context_management response field.
{
"id": "msg_013Zva2CMHLNnXjNJJKqJ2EF",
"type": "message",
"role": "assistant",
"content": [...],
"usage": {...},
"context_management": {
"applied_edits": [
{
"type": "clear_tool_uses_20250919",
"cleared_tool_uses": 8,
"cleared_input_tokens": 50000
}
]
}
}
Together, these new API features really help improve agent performance:
- Enable longer conversations by automatically removing old tool results from context
- Boost accuracy by saving critical information to memory
- Share memories across successive agentic sessions
Token-tracking
One last feature from this launch to help with context management is built-in context awareness via tracking available tokens throughout the conversation. There isn’t much detail in the docs about how this works exactly, but it’s closely intertwined with both the memory and context editing tools.
The Claude Agent SDK: From Model to Application
Anthropic also relaunched their Agents SDK, rebranding it from the Claude Code SDK to the Claude Agent SDK to reflect that it can now power many types of agents.
The SDK essentially handles many of the challenges you’d otherwise need to solve yourself, such as calling tools, managing context, and orchestrating models.
What the SDK Enables
- Memory management: Built-in support for persistent memory.
- Tool orchestration: Define and register tools (APIs, functions, databases) that the model can call as part of its reasoning process.
- Event-driven workflows: Create agents that react to triggers, maintain state, and coordinate multiple tasks.
In practice, this means you can build powerful agents more quickly using a stack fully powered by Anthropic. For reference, here's some more info on OpenAI’s agent SDK. There’s a lot of overlap, but both involve the same explicit choice: tying yourself to a single model provider.
System prompt changes
One great thing about Anthropic is that they always publish their system prompts. We recently did a rundown on the Claude 4 Sonnet system message that you can check out here: An Analysis of the Claude 4 System Prompt.
I ran a quick comparison between Sonnet 4 and 4.5 to see if there were any major changes. Updates in new system messages give some insight into how Anthropic envisions Claude being used and what they’ve learned from real-world usage so far
Full system prompts with tools:
More XML
For all the noise Anthropic has made about using XML in prompts, Claude 4.5 is actually the first system prompt where they use them in a meaningful way.
Sonnet 4:
The original system message is written as one long block of prose. Aside from a single <election_info> tag near the end, it’s mostly plain text — different types of instructions (safety, tone, refusals, formatting, knowledge cutoff) are all mixed together without any clear separation.
Sonnet 4.5:
The new version is broken into distinct XML-style sections, including <behavior_instructions>, <general_claude_info>, <refusal_handling>, <tone_and_formatting>, <user_wellbeing>, <knowledge_cutoff>, and <long_conversation_reminder>.
Analysis:
It’s no secret that LLMs, especially Claude, handle structured instructions better.
Ambiguity Handling
Sonnet 4:
“In general conversation, Claude doesn’t always ask questions but, when it does, it tries to avoid overwhelming the person with more than one question per response.”
Sonnet 4.5:
“Claude does its best to address the user’s query, even if ambiguous, before asking for clarification or additional information.”
Analysis:
The newer version adds a more proactive behavior for Claude to attempt to interpret and respond to unclear queries before asking follow-up questions.
Knowledge Cutoff and Web Search
Sonnet 4:
“Claude’s reliable knowledge cutoff date… is the end of January 2025. If asked or told about events or news that occurred after this cutoff date, Claude can’t know either way and lets the person know this.”
Sonnet 4.5:
“Claude’s reliable knowledge cutoff date… is the end of January 2025… If asked about events that may have occurred after this cutoff date, Claude uses the web search tool to find more information… Claude is especially careful to search when asked about specific binary events.”
Analysis:
This is one of the bigger changes. Instead of simply refusing when information falls beyond its training data, Claude now proactively uses the web search tool. It’s a sign that Anthropic is more confident in Claude’s ability to retrieve and integrate live information reliably.
Long Conversations
Sonnet 4:
(No mention)
Sonnet 4.5:
“Claude may forget its instructions over long conversations. A set of reminders may appear inside <long_conversation_reminder> tags… Claude should behave in accordance with these instructions if they are relevant.”
Analysis:
The new reminder mechanism is designed to combat instruction drift in long chats. Probably using the memory tool under hood!
Philosophical Self-Description (Removed)
Sonnet 4:
“Claude engages with questions about its own consciousness… tries to have a good ‘philosophical immune system’… reframes questions in terms of observable behaviors rather than subjective experiences.”
Sonnet 4.5:
(Removed)
Analysis:
Claude 4.5 drops much of the reflective language around consciousness and self-concept, which felt unnecessary to begin with.
Final Thoughts
Claude Sonnet 4.5 is a meaningful step forward, particularly for long-running tasks like coding. Anthropic’s claim that it can “work for 30 hours straight” still feels more like marketing than reality, but time will tell!That said, it’s an excellent coding model and, in my experience, stands toe-to-toe with GPT-5.




