
In the world of AI, embeddings help LLMs interpret human language.
In this article, we'll define what embeddings actually are, how they function within OpenAI’s models, and how they relate to prompt engineering.
What are embeddings
When you type to a model in human language, it will first translate the language into tokens (more on tokens here).
Embeddings transform those tokens into a format that machines can deeply interpret and learn from. These transformations are usually represented as high-dimensional vector spaces, which are essentially lists of numbers.

Embeddings can relate to images, audio and other types of data. In the context of Natural Language Processing (NLP) embeddings usually refer to text embeddings.
Embedding example
Let’s take the word “dog” as an example. We can’t tell the model to picture a cute four-legged animal with fur, because the model doesn’t understand what that means. Instead, “dog” is translated into a list of numbers called a vector. This list of numbers is the model’s representation of “dog”.
This is the essence of what embeddings are.
Embeddings are generated such that words with similar meanings have similar and related vectors. For example, the vector for “dog” would be closer to “dogs” or “puppy” than “car”. Being closer refers to the distance between the vectors in the high-dimensional space, as you can see below.
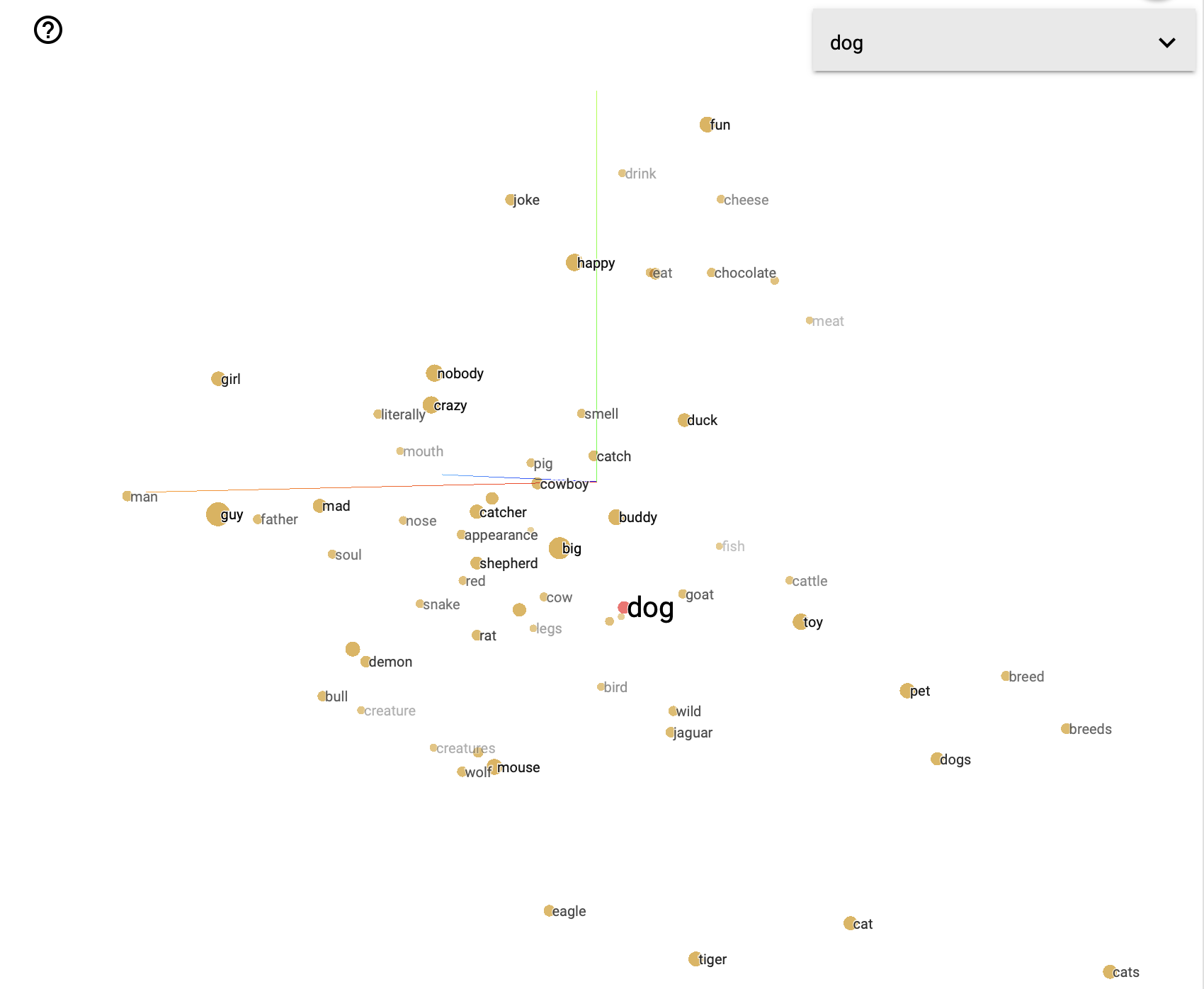
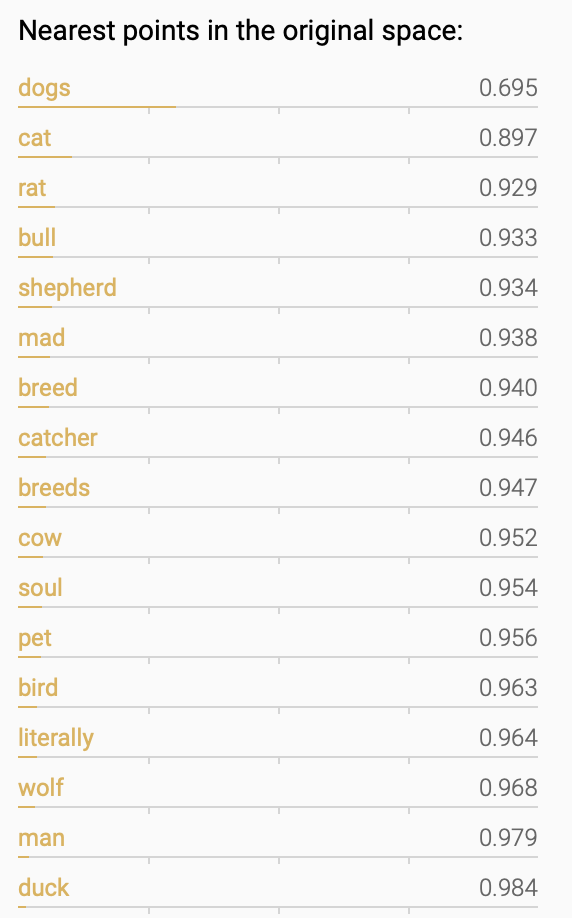
Doing this enables the machine to better analyze relationships between different words, even though it’s never seen a dog or knows anything about what a dog actually is.
Now let’s check out how OpenAI’s models use embeddings to interpret and generate text.
Embeddings in OpenAI models
Alright, so we’ve transformed the text into tokens and the tokens have now been transformed into a high dimensional vector. So, what’s next?
At the core of OpenAI’s models like GPT-3 and GPT-4 is a type of neural network architecture called transformers. Transformers takes word vectors and use them to interpret not only the words themselves, but the context in which they’re used.
Let's go back to our dog example. If the sentence was “I took the dog for a walk”, the transformer would consider the word "dog" + all the other words in the sentence to figure out the context. It uses these other words to "understand" that “dog” is referring to a dog that we could have as a pet and can take for walks.
Transformers use the vectors to process the relationship between words in a sentence, not just the individual words themeslves. This is what enables the model really interpret grammar and context.
How transformers pay attention
Not every word holds the same contextual importance in a sentence, so it wouldn’t make sense for a transformer to spend its energy equally amongst words in a sentence.
Transformers have a mechanism called attention that allows the model to focus on different parts of the input when generating each word.
For instance, let’s take a look at the sentence, “despite the rain, they enjoyed their picnic”. The words “despite”, “rain”, and “enjoyed” hold important relationships in the sentence because they’re key to understanding the main event and how it was influenced by certain conditions.
When processing the word “enjoyed”, the model pays more attention to the words “despite” and “rain”. It does so because together they provide important context for the enjoyment. It's not just that they enjoyed their picnic, but they enjoyed it in spite of a condition that might typically detract from the enjoyment of a picnic (the rain).
Attention helps transformers generate responses that are not only grammatically correct, but also contextually coherent. It’s one of the key reasons why OpenAI’s models are able to interpret and generate text that feels so human-like.
Understanding embeddings for prompt engineering
Prompt engineering is all about writing prompts to get desired outputs. When you give prompts to models like GPT-4, you’re giving the model a series of vectors - the embeddings of those words - which the model will use to generate its response.
Knowing how models understand and relate text gives us a few tools we can leverage when writing and improving prompts.
Precision - By understanding how words are represented as vectors, we can make more informed decisions about which words to use in our prompts.
Context - As we saw in the examples above, AI models don’t just consider each word in isolation, they look at the relation between the words. Knowing this, we can structure our prompts to provide the right context for the response we want.
Interpretability - If a model’s response doesn’t line up with what we expected, understanding embeddings can help us figure out why. We can look at the embeddings of the words in our prompt to get insights into what relationships the model might have drawn on.
Improving prompts with a deeper understanding of embeddings
Let’s put this into practice.
Precision
Let’s say we want to write a story about a brave knight. We might write a prompt like “Tell me a story about a knight”. This prompt could result in a variety of stories that might not align with our intent.
But since we understand embeddings, we know we can and should be more specific with our language. So we can update our prompt to be "Tell me a thrilling tale about a brave knight facing a fearsome dragon". This prompt provides more vectors for the model to grab onto, increasing the chances that the resulting story will line up with what we want.
Context
Let’s say we want the model to describe the benefits of exercise. A simple prompt like "Talk about exercise" will probably give us a generic output about exercise. However, if we provide more context, such as "Discuss the physical and mental health benefits of regular cardiovascular exercise for adults," we give the model more words and relationships between words to give better responses.
Interpretability
If we give the model a prompt and it generates an unexpected response, we can analyze the specific embeddings of the words in our prompt and the model’s response. We might find that certain words in our prompt had embeddings that the model associated with a different meaning.
This may be a little difficult to do, but it can significantly improve your output. Specifically you can do the following.
-Review the prompt - Look closely at the words for any that may have multiple meanings
-Compare to good outputs - Compare the unexpected output to outputs that are more in-line with what you want. Can you see any any patterns, or word changes that might give you a clue?
As always, writing good prompts is an iterative process and takes time!
Takeaways
- An LLM turns words into tokens, and each token is then transformed into a high-dimensional vector using an embedding technique.
- Embeddings capture the meaning of the words, and their context within a sentence.
- The attention mechanism in transformers help determine which words are the most crucial to understand in a sentence.
- Understanding embeddings can help you with prompt engineering through precision, understanding context, and interpretability.
Now you know that, through embeddings, every word you choose while writing prompts carries significant weight. Happy prompt engineering!





