
Part of the reason that GPT-5 is getting such mixed reactions comes from the fact that it requires a different approach to unlock its full potential compared to earlier OpenAI models.
At its core, GPT-5 was trained for agentic apps. Like GPT-4.1, it’s highly steerable and will closely follow your instructions. This is very different from the o-series models.
It’s notably better at tool use, long-context understanding, and executing long-running tasks with higher accuracy.
In practice, the three levers that matter most are reasoning_effort, verbosity, and tool preambles.
In this post we’ll run through all the best practices to get optimal results from GPT-5.
Controlling Eagerness
GPT-5 is highly steerable. It will closely follow your instructions, but through reasoning, it can also make high-level decisions when instructions aren’t clear.
For faster answers, set the reasoning_effort parameter to minimal or low. For most tasks, low or medium is probably enough to get accurate results without huge hits to speed.
Since the model is very steerable, you can also influence speed directly in your prompt.
Here’s an example from OpenAI:
You can take it further by setting fixed tool call budgets in the prompt. We’ve seen this in our analysis of the Claude 4 system prompt, excerpt below:
Queries in the Research category need 2-20 tool calls … complex queries require AT LEAST 5.
Example from OpenAI for faster responses with less reasoning:
OpenAI goes on to say the following in their prompting guide:
When limiting core context gathering behavior, it’s helpful to explicitly provide the model with an escape hatch that makes it easier to satisfy a shorter context gathering step. Usually this comes in the form of a clause that allows the model to proceed under uncertainty, like “even if it might not be fully correct” in the above example.
This was surprising to read, as that clause seems like it could have unintended consequences. Having an escape hatch is important, but I would lighten the clause to be something like:
<uncertainty_policy>
If you are uncertain after X rounds of gather context, then produce a provisional recommendation ONLY.
List assumptions + unknowns. Mark output as "Provisional".
</uncertainty_policy>
On the flip side, if you want GPT-5 to think more deeply, call more tools, and operate with greater autonomy, you have a couple of levers.
First, set reasoning_effort to high. This gives the model more capacity to plan and consider alternatives.
Then, as we saw before, you can use your prompt instructions to reinforce this behavior. Explicit instructions can encourage the model to explore options, verify work, and persist through multi-step tasks.
Example from OpenAI:
An important note when extending reasoning_effort is that you still should give the model a stop condition, espescially in agentic tasks.
Other important notes about reasoning efforts
- Tool calling:
reasoning_effortaffects not just how much reasoning text the model produces, but also how readily it decides to call tools. - Complex workflows: For multi-step tasks, higher reasoning can help, but you’ll often get better results by breaking big jobs into smaller, single-purpose agent turns. One turn per task generally improves reliability.
- Coding tasks: Minimal
reasoning_effortoften works well for code, but if you want the model to be a bit more proactive and consider broader context, add light chain-of-thought prompting. Even a simple instruction to “think through the steps” or “outline before answering” can help.
Tool Preambles
A few months ago Anthropic launched extended thinking, which let Claude share more of its reasoning steps and tool calls directly with the user (a big UX upgrade).
Tool preambles are OpenAI’s version of that feature essentially. They let GPT-5 narrate what it’s doing and why before executing a tool call, giving users better visibility into its process.
Here is a code example from Claude:
{
"content": [
{
"type": "thinking",
"thinking": "Let me analyze this step by step...",
"signature": "WaUjzqIOMfFG/UvLEczmEsUjavL...."
},
{
"type": "text",
"text": "Based on my analysis..."
}
]
}
OpenAI’s tool preambles let GPT-5 send intermittent updates while it’s reasoning and calling tools. The model is specifically trained to:
- Provide a plan up front so you know the intended approach.
- Send progress updates through tool preamble messages as it works.
To enable this, include the following in your API request:
"reasoning": {
"summary": "auto" //other options is "detailed"
},
You can and should also reinforce tool preamble behavior in your prompt, not just through API settings. Clear instructions help GPT-5 provide richer, more useful updates.
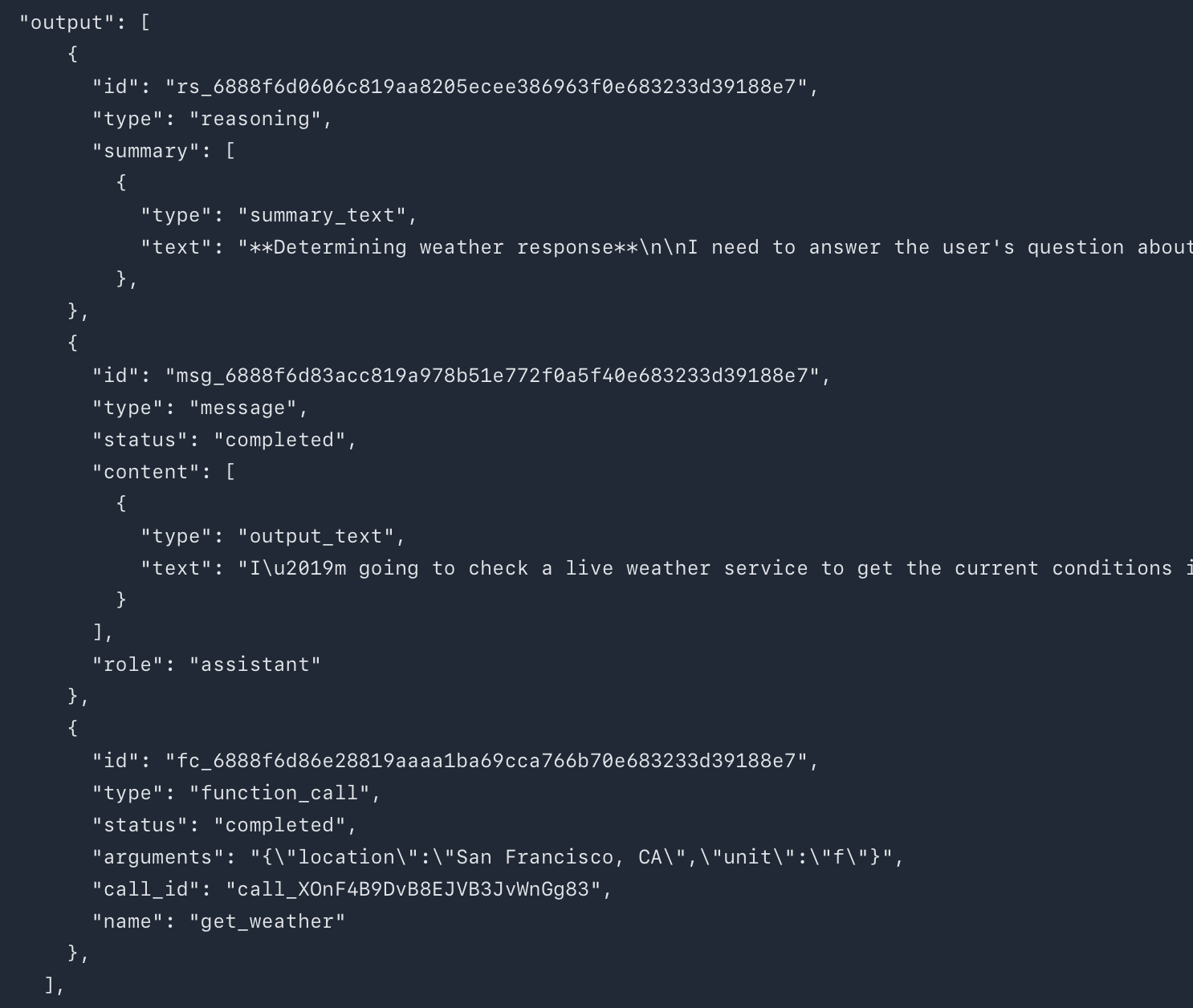
Something important to note is that your organization must be verified to generate reasoning summaries.
Verbosity
verbosity is a new API parameter in GPT-5 that controls how long the final output is, in a different way than max_tokens (which essentially sets a hard cap). It only affects the length of the model’s answer, not the length of its internal reasoning or tool calls, those are governed by reasoning_effort.
Verbosity can be set to the following values:
Like other behaviors in GPT-5, verbosity can be enhanced or overridden in your prompt. For example, you might set a global verbosity level in the API, but give task-specific overrides in certain tools or contexts.
A good example comes from Cursor. When they upgraded to GPT-5, they noticed the model’s outputs became overly verbose in general conversation, which hurt UX. However, code generated inside tool calls was sometimes too short. Their fix:
- Set the global API verbosity to
lowfor concise everyday outputs. - Add prompt instructions for verbose outputs only when using coding tools.
This combination gave their users faster and shorter responses in chat, while keeping code outputs clear and well-formatted.
Use Responses API, not Chat Completions
When using GPT-5 it is generally better to use the Responses API so you can pass a previous_response_id and let the model reuse prior reasoning traces. In OpenAI’s evals, switching the endpoint alone improved Tau-Bench Retail from 73.9% → 78.2%.
Framework and package preferences
GPT-5 can work with most common web development frameworks, but to get the most out of its frontend capabilities, OpenAI suggests the following:
- Frameworks: Next.js (TypeScript), React, HTML
- Styling / UI: Tailwind CSS, shadcn/ui, Radix Themes
- Icons: Material Symbols, Heroicons, Lucide
- Animation: Motion
- Fonts: Sans Serif, Inter, Geist, Mona Sans, IBM Plex Sans, Manrope
Below is a self-reflection example for zero-to-one coding projects.
Below is an example prompt from OpenAI for guiding the model to match codebase design standards.
Tuning old prompts to work well with GPT-5
One key difference with GPT-5, and why it can feel slower, is that it’s naturally more introspective and proactive when gathering context. If your older prompts already contained detailed instructions for information gathering or extended reasoning, you may need to tone those down to avoid overthinking.
For example, Cursor had the snippet below in one of their main prompts.
This approach worked well for older models, but not as much with GPT-5. It caused the model to overuse tool calls doing repetitive searches.
To fix this, Cursor removed the maximize_prefix and softened the language around thoroughness. This tweak led GPT-5 to make smarter decisions about when to rely on its internal knowledge versus when to call tools for external information, improving both efficiency and response quality.
Instruction following
As mentioned earlier, GPT-4.1 and GPT-5 are similar in that they both follow prompt instructions with high precision. This is a double-edged sword: it makes them powerful for a wide range of workflows, but it also means they are more vulnerable to poorly constructed prompts, especially those containing contradictory instructions.
With GPT-5, this is an even bigger concern since it is a reasoning model. It will often burn reasoning tokens trying to reconcile contradictions that can’t actually be resolved, slowing responses and reducing output quality.
From working with many teams on prompt design, we’ve found contradictory instructions to be a major source of performance issues. An effective way to solve this quickly is to have another teammate review the prompt themselves to see if there are any contradictions, or if anything is unclear about the task.
Minimal reasoning and prompting best practices
GPT-5 introduces a new minimal reasoning level. Previously, you could only set reasoning effort to low, medium, or high. Minimal is now the fastest option, while still offering the advantages of a reasoning model.
Many best practices from our GPT-4.1 prompt engineering guide still apply, but with minimal reasoning, the model has fewer reasoning tokens, so your prompt design becomes even more important.
- Summarize upfront – For challenging tasks, prompt the model to briefly outline its thought process at the start of the final answer.
- Descriptive tool preambles – Instruct the model to provide rich tool-calling preambles so the user stays updated and agent performance improves.
- Disambiguate tool instructions – Keep instructions clear and distinct so the model doesn’t waste limited reasoning on deciding which tool to use.
- Persistence reminders – Add explicit instructions telling the model to keep working until the task is fully resolved. This helps prevent early termination in long-running tasks.
- Developer-led planning – Since minimal reasoning reduces the model’s own planning capacity, take on more responsibility for clearly communicating the full task plan in your prompt.
Here’s an example snippet below from OpenAI that they use on an agentic task. Note that in the second paragraph they insert those reminders so that the agent completes the task fully.
Meta prompting
As always, you should use LLMs when working on prompts! In PromptHub we have a variety of tools like our prompt enhancers and our prompt generator. For more information about meta prompting you can check out our guide here.
Below is a meta prompting template from OpenAI
Conclusion
GPT-5 rewards clear, intentional prompt design. It thrives on specificity, but, when given the room to reason, can fill in gaps and make smart, autonomous decisions. Here is the TL;DR:
- Be specific: Reduce ambiguity in instructions to avoid wasted reasoning tokens.
- Tune reasoning effort: Minimal for speed, high for complex, multi-step workflows.
- Leverage tool preambles: Keep users informed and improve multi-step agent reliability.
- Set persistence reminders: Prevent early termination in long-running tasks.
- Plan in the prompt: Especially important when reasoning tokens are limited.
- Iterate gradually: Small prompt changes let you see exactly what drives improvements.




