
Just this week Anthropic's Claude 4 Sonnet (LINK) became the latest model to support a 1 million token context window. Context limits keep increasing, and the model providers keep reporting perfect needle-in-a-haystack performance, but how do these models actually perform in the wild when faced with massive context?
Chroma’s recent paper, Context Rot: How Increasing Input Tokens Impacts LLM Performance, offers one of the clearest and most up-to-date looks at where models start to falter when given large context.
Below, we'll run through all the experiments they ran, unpack what each means, and the takeaways for anyone using LLMs today.
Chroma ran their experiments across 18 LLMs, including state-of-the-art models like GPT-4.1, Claude 4, Gemini 2.5, and Qwen 3 models.
Experiment 1: Needle-in-a-Haystack, but with controlled ambiguity
Goal: Test how semantic closeness between the question and the “needle” affects performance as inputs grow.
Setup:
- Two corpora for haystacks: Paul Graham essays and arXiv papers.
- Cluster each corpus to find common themes.
- Write one question per theme (below), ensure the haystack does not already contain the answer, and then hand-write 8 needles per question. This ensures no alternative answers exist and that incorrect answers have to be hallucinations

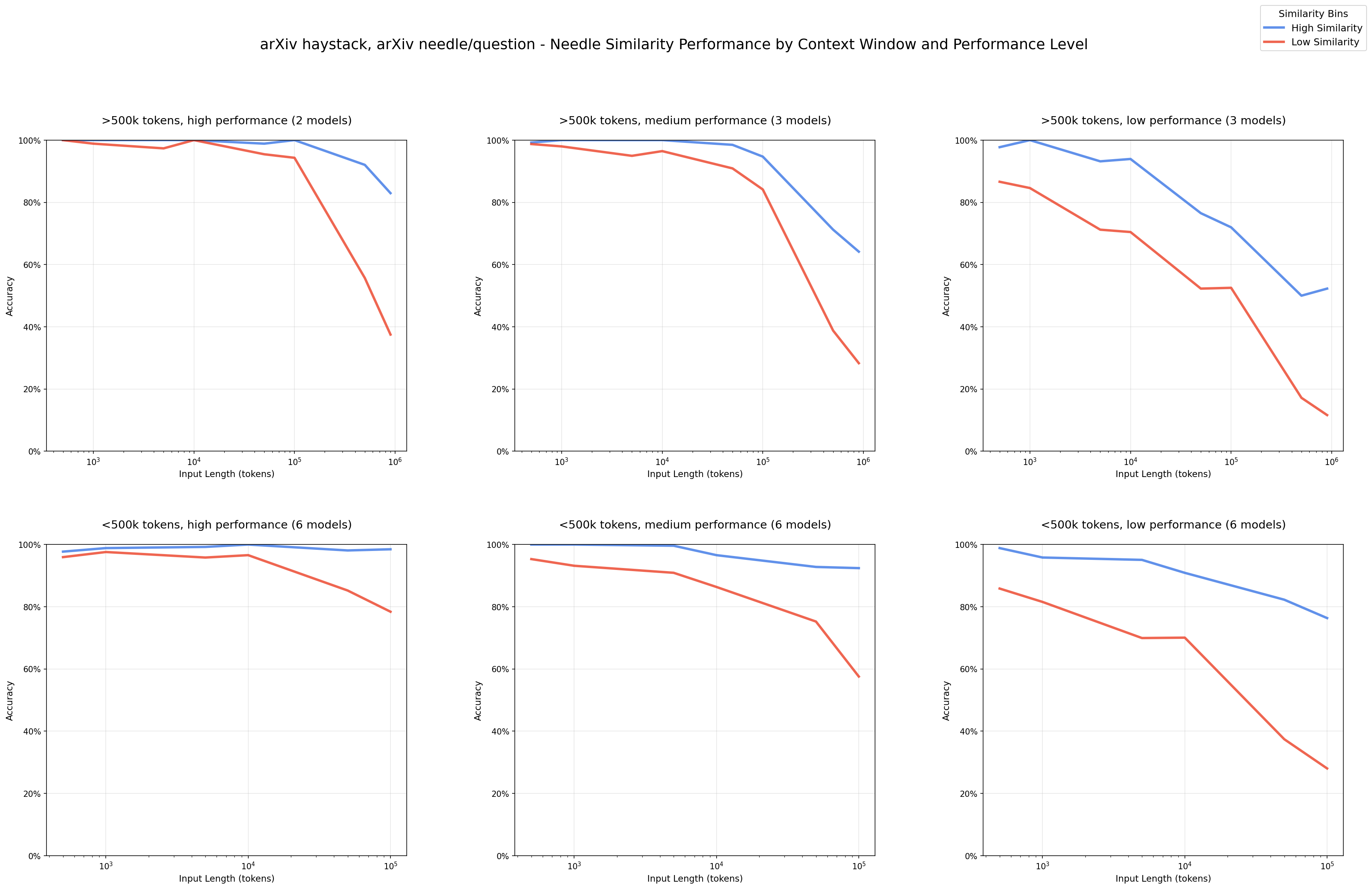
What happens:
At short lengths (thousands of tokens), high performance models perform well. As length grows, lower similarity pairs fall off faster (red line). The same question/needle pair gets harder only because more irrelevant text surrounds it.
Why it matters:
If your question and supporting snippet aren’t tightly aligned semantically, which they usually aren't, with more context, performance will decrease, even when the right snippet is present.
Experiment 2: How distractors affect LLM performance
Goal: What impact do distractors have in long contexts? Do all distractors hurt equally?
Setup:
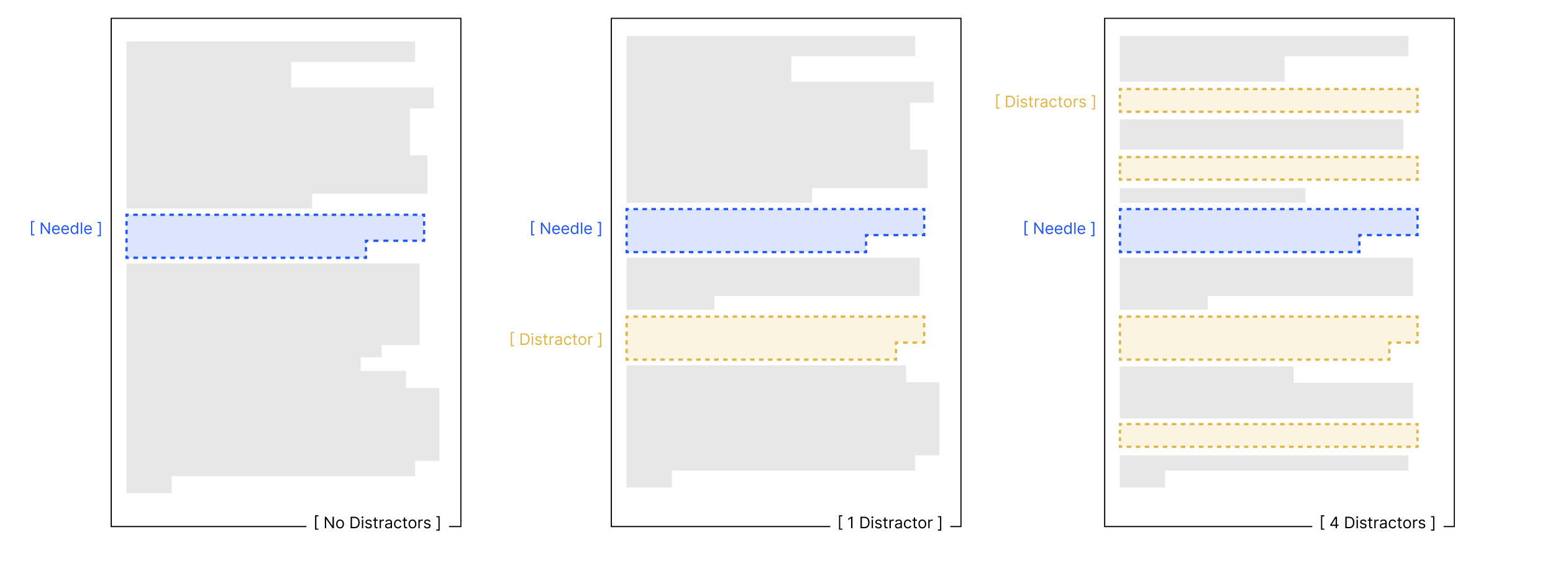
For each topic (PG essays and arXiv papers), they took a high-similarity needle-question pair and created four hand-written distractors that look plausibly relevant (see below).

They tested three conditions as length grows:
- Needle only (no distractors)
- One distractor, randomly positioned
- Four distractors, randomly positioned
What happens:
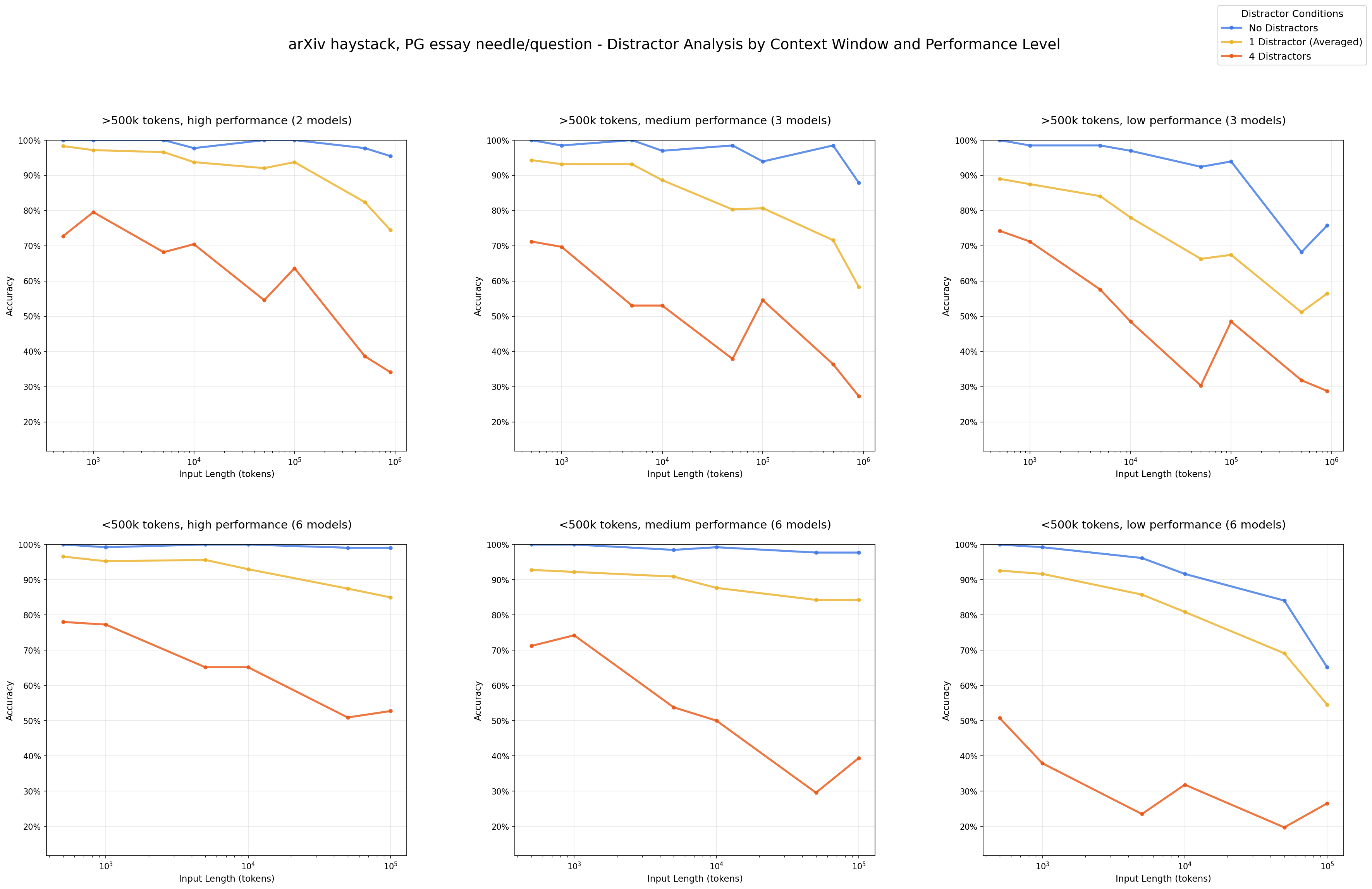
- Even one distractor reduces accuracy versus baseline.
- Four distractors compound the damage.
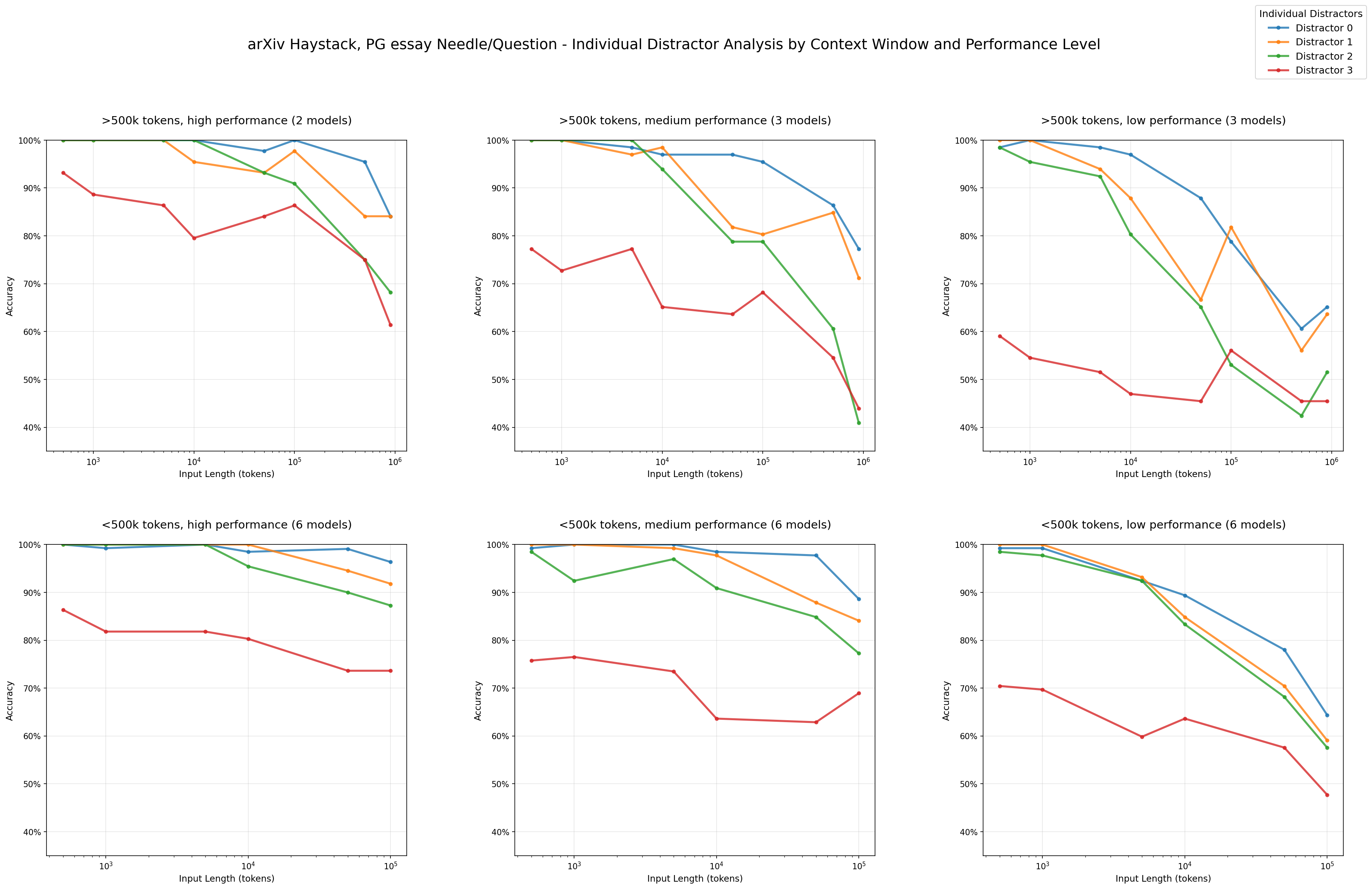
- Not all distractors are equal some consistently derail models more than others(see red line above).
- Behavior differs by model family
- Anthropic models have the lowest hallucination rates and tend to abstain when uncertain (Especially Claude 4)
- OpenAI models have the highest hallucination rate. Often confidently generating wrong answers
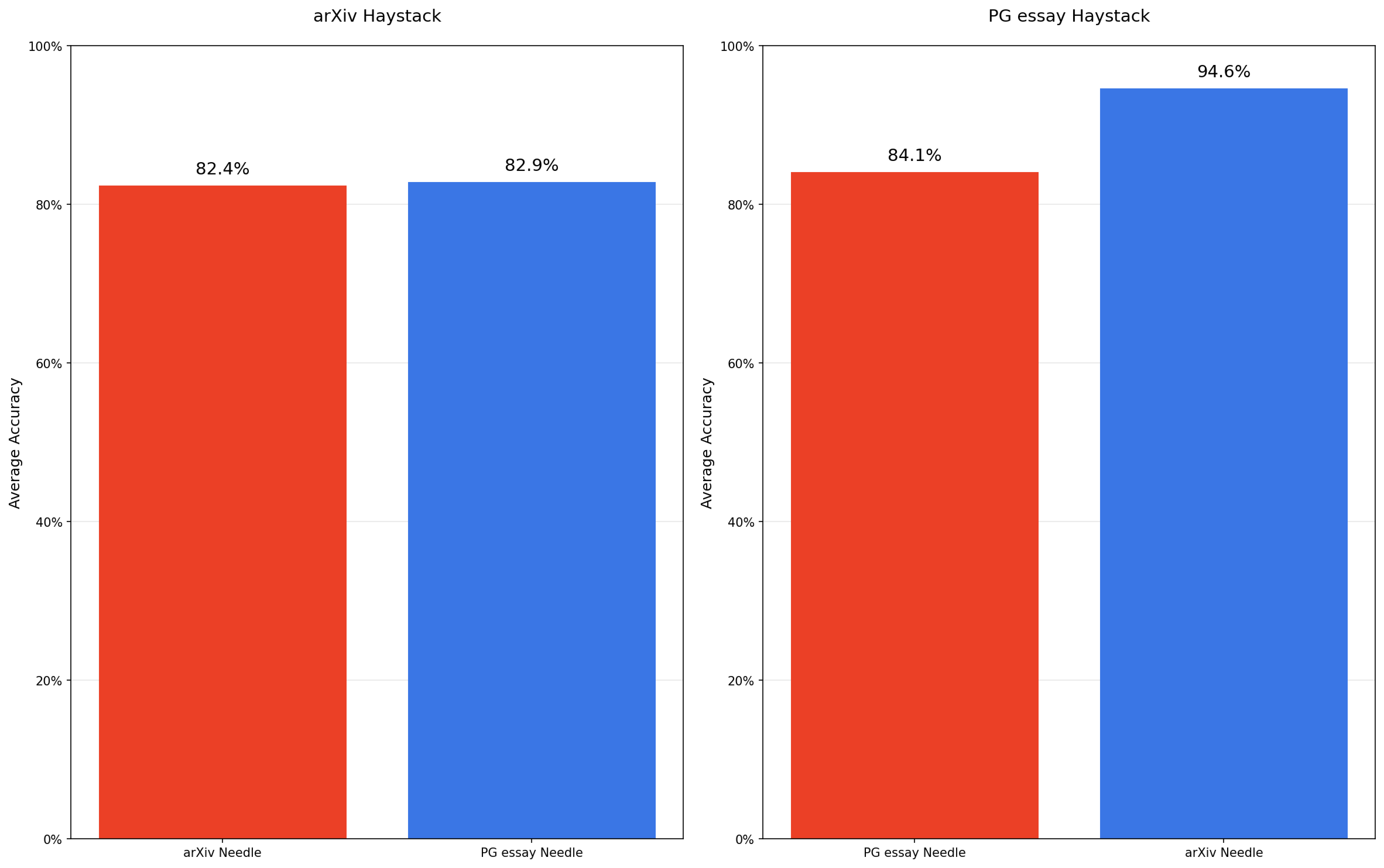
Experiment 3: Needle–Haystack similarity
Goal: Usually in experiments, irrelevant context is jammed into the context window to increase length. But what if the haystack resembles the needle thematically? Does that make retrieval harder as length grows?
Setup: The setup can be descirbed in one image:

What happens: Effects are non-uniform.
- In PG haystacks, out-of-domain (arXiv) needles performed better than in-domain needles (i.e., blending in did hurt).
- In arXiv haystacks, the difference was small.
Why it matters:
While this isn’t enough data to draw firm conclusions about the effects of needle–haystack similarity, it does highlight the uneven performance patterns that emerge in long-context tasks.
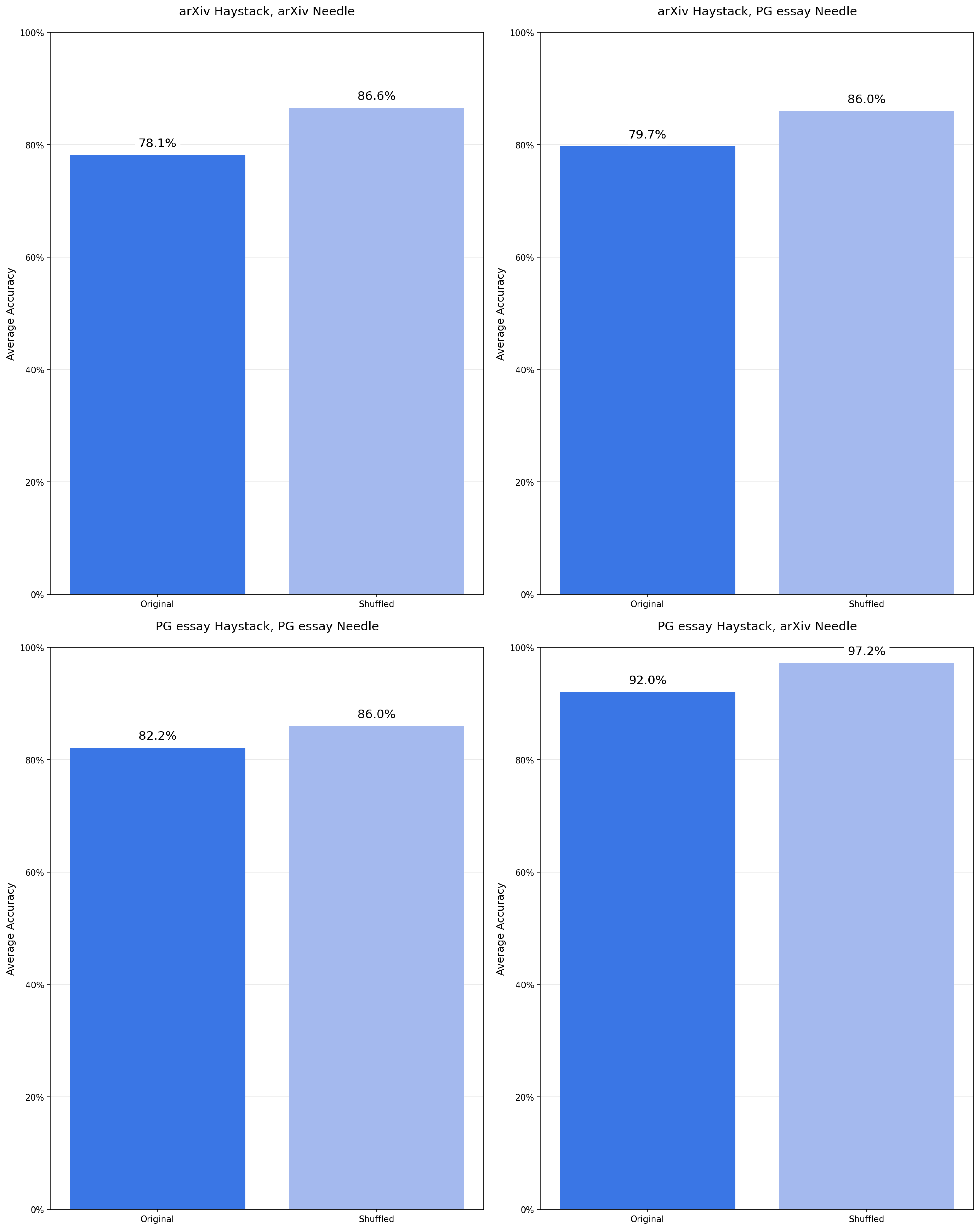
Experiment 4: Haystack structure (coherent vs. shuffled)
Goal: Does the structure of the haystack affect performance? Would a needle injected into the middle of an essay make it more noticeable? Would a haystack of a bunch of random sentences better hide the needle?
Setup: Two variants
- Original: Needle is injected into the middle of a coherent article
- Shuffled: Sentences, all from the same essay, are randomly reordered throughout the haystack. Same topic, but without the same continuity.

What happens: Shuffled outperforms Original across 18 models! Counterintuitive, but consistent!
Why it matters:
This one was maybe the biggest shocker. It may shed some light on the model's attention mechanism, especially as input length increases.
Experiment 5: Multi-turn QA with long chat history (LongMemEval)
Goal: Measure how much adding irrelevant chat history hurts answer quality.
Setup:
Two conditions per question were tested:
- Focused input (~300 tokens): Contains only relevant information from the chat history
- Full input (~113k tokens): Contains the whole chat history
Grading via GPT-4.1 aligned judge (>99% agreement with humans in their checks).
What happens:
All model families do much better with focused inputs rather than with the full chat history. But the difference in performance varies a lot based on model provider.
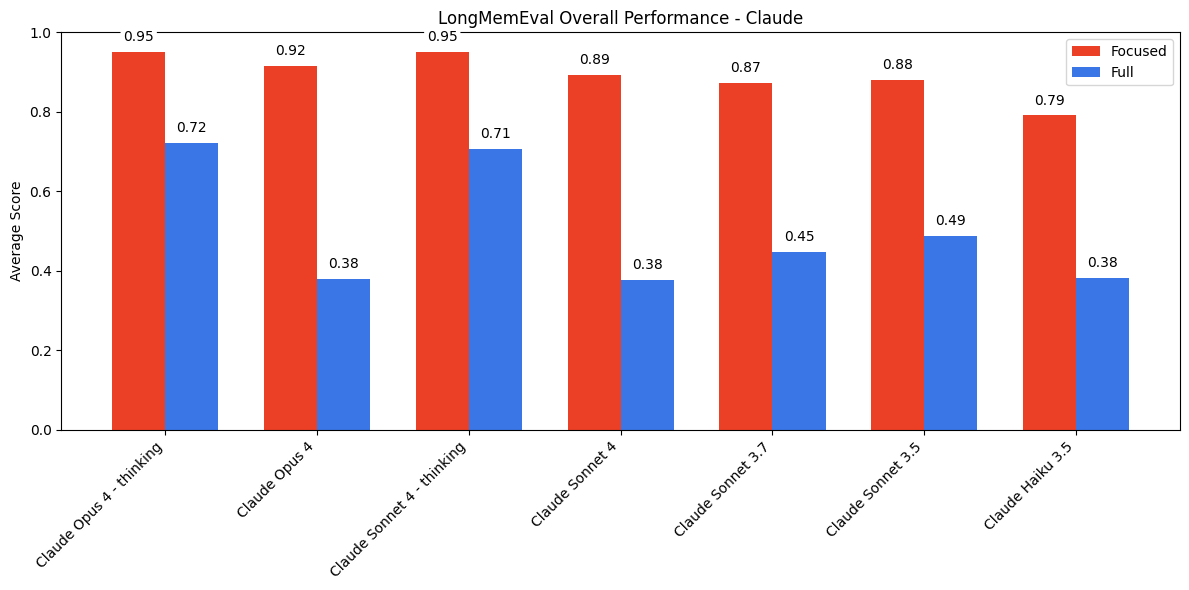
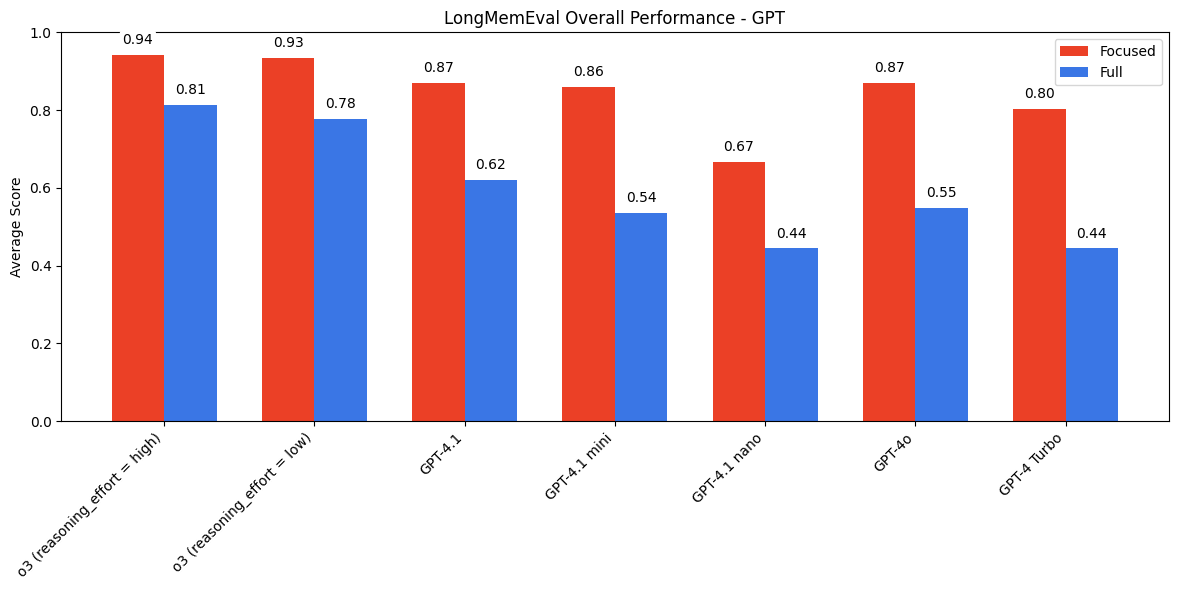
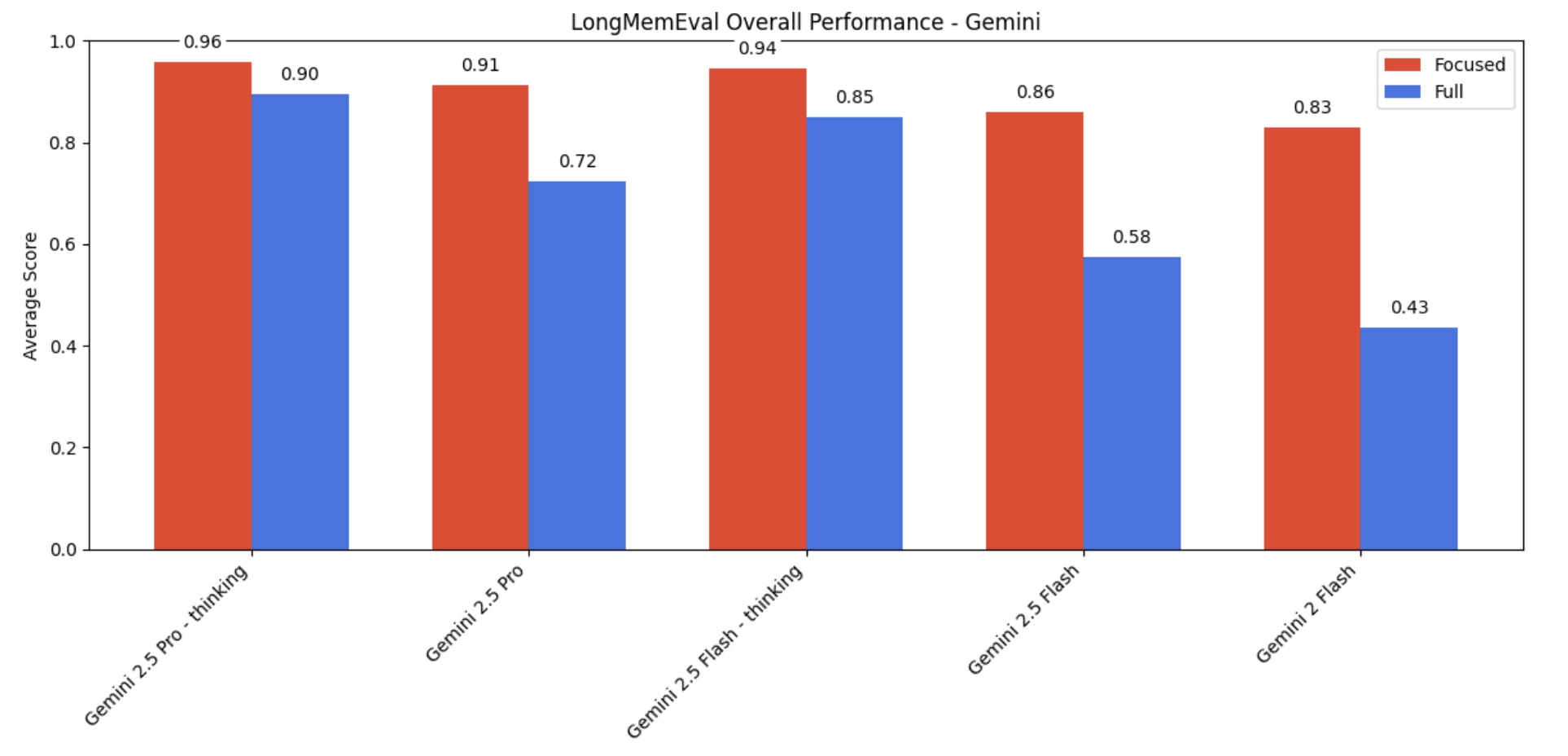
- Anthropic models show the biggest gap, often abstaining (like in the disrtactors expeirment above) on the full input where they would have answered correctly on the focused version.
- “Thinking” modes do better, but a gap still remains
- OpenAI models perform pretty well, and Gemini models perform the best
Why it matters:
This is key for anyone building with LLMs who have to manage context windows, espically if you are using models from Anthropic. Long live RAG!
Conclusion
This paper from Chroma is one of the better, non-biased, reports on where we are at today with long context windows. Thanks to the team for publishing!




